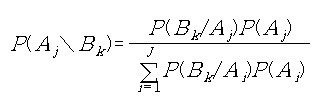이 책은 '14년 7월 초판 1쇄 발행한 책으로 2022년 6월 현재 2판 1쇄 발행본으로 전면 개정판이다. 베이즈 추론은 통계학을 전공한 사람들은 잘 알겠지만 예전에는 통계학개론 과목에 한개 챕터 정도로 넘어가던 내용이 었으나 최근 머신러닝이 빅데이터를 활용하고 이를 수정해 나가며 원하는 해를 구하는 방식이 베이즈 추론의 로직과 유사하며 전산 환경이 어마어마하게 발달함에 따라 이제는 이론이 아닌 실제 구현을 해볼 수 있는 수준에 도달하게 되었다.
기억하기로는 대학원에서 특론 등으로 강좌가 개설되던 것이 중요성이 점차 증대함에 따라 이제는 학부에서도 한 학기 3학점 과목으로 개설되는 대학도 늘어나고 있다. 하지만 아직 실제 예제를 활용하는 부분에 포커스를 맞추기 보다는 수리통계적 접근이 더 강한 강단 환경으로 프로그래머, 직장인, 실습을 병행하고 싶어하는 학생들에게는 일말의 아쉬움이 있었는데 본 책을 통해 이러한 갈증을 해소할 수 있을듯 보여 매우 기쁘게 생각된다.
책 저자 앨런 B. 다우니 (Allen B. Downey)는 매사추세츠 보스턴 소재 올린 공과대학교(Olin College of Engineering) 전산학과 교수로 MIT에서 학석사를 수여받았으며, 캘리포니아 버클리대학에서 박사학위를 받았다.
저자의 약력에서 살펴볼 수 있듯 본 책 내용은 기본적으로 대학 교과서 편제로 챕터가 구성되어 있으나 뜬 구름 잡는 내용이 아닌 실제 회사에서 많이 사용하는 예제와 실제 코드를 적용하여 실무자에게 많은 도움이 되어 보인다.
본문은 409페이지 가량의 분량으로 보이며 책상앞에 두어도 큰 부담이 되지는 않고 총 20장으로 구성되어 있다. 그 내용을 간단히 살펴보면,
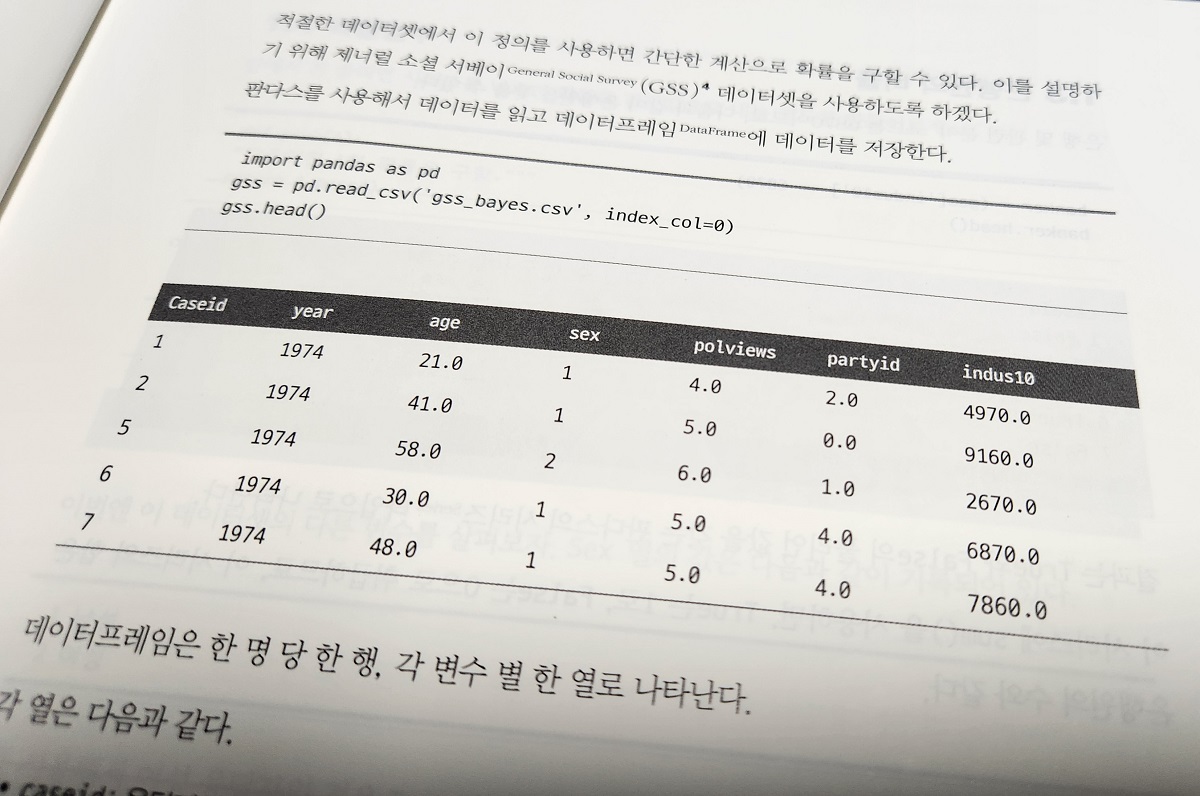
1장은 가볍게 은행원 린다 사례를 통해 베이즈 이론에 대한 이해를 돕고있으며 베이즈 통계를 위한 확률이론의 설명을 통해 워밍업을 하고 있으며 앞에서도 언급했듯이 답답한 이론서 체제가 아닌 실습서에 가까운 편제로 다양한 예제를 삽입하고 있다.
2장은 베이즈 정리에 대한 더 깊은 이해를 위한 쿠키문제, 통시적 베이즈, 베이즈 테이블, 주사위문제, 몬티 홀 문제 등을 다루고 있다.
3장은 분포, 확률 질량함수등을 언급하고 있으며 101개의 쿠키그릇, 주사위 문제, 주사위 갱신등을 언급하고 있으며 챕터 마지막엔 모든 장과 마찬가지로 연습문제로 마무리 하고 있다.
4장은 유로 동전문제, 이항분포, 베이지안 추정, 삼각사전분포 등을 설명하고 있다.
5장은 기관차 문제, 사전확률에 대한 민감도, 역법칙 사전확률, 독일 탱크 문제, 정보성 사전확률 등을 다루고 있다.
6장은 공산과 가산을 다루고 있으며 글루텐문제 등을 다루고 있다.
7장은 최소값, 최대값, 혼합 분포에 대해 설명하고 있다.
8장은 포아송 과정을 월드컵 문제와 더불어 감마분호, 지수분포등 여러 분포 등을 언급하고 있다.
9장은 의사결정 분석을 우승확률, '그 가격이 적당해요' 문제 등을 이용해 보여주고 있다.
10장은 검정에 대한 주제를 밴딧 사례등을 통해 다루고 있다.
11장은 비교에 대해 다루고 있으며 외적연산, 결합분포, 주변분포, 사후조건부확률 등을 다루고 있다.
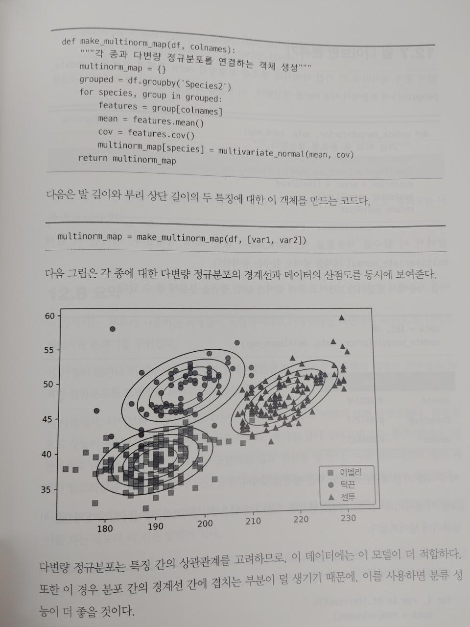
12장은 분류에 관하여 펭귄데이타, 정규모델, 갱신, 나이브 베이지안 분류, 다변량 정규분포 등을 보여준다.
13장은 추론을 설명하며 매개변수 추정, 사후 주변분포, 요약통계 사용하기 등에 대해 다루고 있다.
14장은 생명보험등 의학 연구등에 많이 이용되는 생존 분석에 대해 다루고 있으며 와이블 분포, 사후평균, 사후예측분포에 대해 이야기 하고 있다.
15장은 표식과 재포획을 다루고 있으며 그리즐 곰 문제, 두 개의 매개변수를 사용하는 모델, 링컨 지수 문제 등을 언급하고 있다.
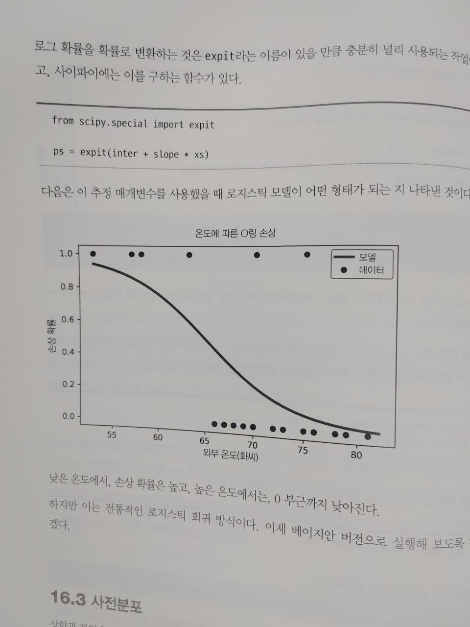
16장은 로지스틱 회귀를 학습하며 로그공산, 우주 왕복선 문제, 사전분포, 가능도, 갱신등에 대해 공부하고 있다.
17장은 회귀를 배우며 마라톤 세계 신기록, 사전분포 등을 학습하고 있다.
18장은 켤레사전분포에 관하여 다시 만난 월드컵 문제, 이항가능도, 디리클레 분포 등을 설명하고 있다.
19장은 MCMC에 대해 공부하며 월드컵 문제, 그리드 근사 등을 배우고 있다.
20장은 마지막 장으로 근사 베이지안 계산을 신장 종양 문제, 시뮬레이션, 세포 수 측정 등으로 책 내용을 마무리 하고 있다.
전체적인 총평은 난이도 중급으로 베이지안 통계에 대하여 여러 예제를 삽입하여 추상적인 내용을 구체적으로 이해하도록 잘 구성하였는데 기본적으로 프로그래밍언어(파이썬), 통계학개론(여러 분포, 검정, 추정, 회귀등)에 대한 이해가 선행되어야 할 것으로 보이며 분류등 머신러닝에 대한 기초적인 이해가 있다면 본 책을 더 쉽게 학습하는데 도움이 될 것으로 사료된다.
"한빛미디어 <나는 리뷰어다> 활동을 위해서 책을 제공받아 작성된 서평입니다."