이게 읽히나요?
번역 상태 심각합니다.
좋다고 별 4개 5개 주신 분들은 당최 어떻게 읽으신지 상상이 안되네요
한 권으로 정리하는 스파크 스트리밍
데이터를 실시간으로 처리하는 방법을 안다면, 분석 도구로 빠르게 인사이트를 얻을 수 있다. 이 책은 아파치 스파크를 기반으로 인메모리 프레임워크를 사용해 스트리밍 데이터를 처리하는 방법을 학습한다. 또한, 스파크로 어떻게 배치 작업하듯이 스트리밍 작업을 수행할 수 있는지를 다룬다.
이 책은 아파치 스파크의 이론과 예제를 학습하는 데 중점을 두었으며, 스파크가 현재 지원하는 스파크 스트리밍 라이브러리와 최신 구조적 스트리밍 API를 배울 수 있다. 스트리밍 애플리케이션에 아파치 스파크를 적용하려는 독자라면 스트림 처리의 기본 개념부터 머신러닝을 포함한 고급 기술까지 다양한 인사이트를 얻을 수 있을 것이다.

[Part 1 아파치 스파크를 사용한 스트림 처리의 기본]
CHAPTER 1 스트림 처리 소개
1.1 스트림 처리란
1.2 스트림 처리 예제
1.3 데이터 처리의 확장
1.4 분산 스트림 처리
1.5 아파치 스파크 소개
1.6 다음엔 무엇을 배울까
CHAPTER 2 스트림 처리 모델
2.1 소스와 싱크
2.2 서로 정의된 불변의 스트림
2.3 변환과 집계
2.4 윈도우 집계
2.5 비상태 및 상태 기반 처리
2.6 상태 기반 스트림
2.7 예제: 스칼라에서 로컬 상태 기반 연산
2.8 비상태 또는 상태 기반 스트리밍
2.9 시간의 영향
2.10 요약
CHAPTER 3 스트리밍 아키텍처
3.1 데이터 플랫폼의 구성 요소
3.2 아키텍처
3.3 스트리밍 애플리케이션에서 배치 처리 구성 요소의 사용
3.4 참조 스트리밍 아키텍처
3.5 스트리밍과 배치 알고리즘
3.6 요약
CHAPTER 4 스트림 처리 엔진으로서의 아파치 스파크
4.1 두 API 이야기
4.2 스파크의 메모리 사용
4.3 지연 시간에 대한 이해
4.4 처리량 지향 처리
4.5 스파크의 폴리글랏 API
4.6 데이터 분석의 빠른 구현
4.7 스파크에 대해 더 알아보기
4.8 요약
CHAPTER 5 스파크의 분산 처리 모델
5.1 클러스터 매니저를 활용한 아파치 스파크 실행
5.2 스파크 자체 클러스터 매니저
5.3 분산 시스템에서의 복원력과 내결함성 이해
5.4 데이터 전송 의미론
5.5 마이크로배칭과 한 번에 한 요소
5.6 마이크로배치와 한 번에 한 레코드 처리 방식을 더욱 가깝게 만들기
5.7 동적 배치 간격
5.8 구조적 스트리밍 처리 모델
CHAPTER 6 스파크의 복원력 모델
6.1 스파크의 탄력적인 분산 데이터셋
6.2 스파크 컴포넌트
6.3 스파크의 내결함성 보장
6.4 요약
[Part 2 구조적 스트리밍]
CHAPTER 7 구조적 스트리밍 소개
7.1 구조적 스트리밍의 첫걸음
7.2 배치 분석
7.3 스트리밍 분석
7.4 요약
CHAPTER 8 구조적 스트리밍 프로그래밍 모델
8.1 스파크 초기화
8.2 소스: 스트리밍 데이터 수집
8.3 스트리밍 데이터 변환
8.4 싱크: 결과 데이터 출력
8.5 요약
CHAPTER 9 구조적 스트리밍 작동
9.1 스트리밍 소스 소비하기
9.2 애플리케이션 로직
9.3 스트리밍 싱크에 쓰기
9.4 요약
CHAPTER 10 구조적 스트리밍 소스
10.1 소스의 이해
10.2 사용 가능한 소스
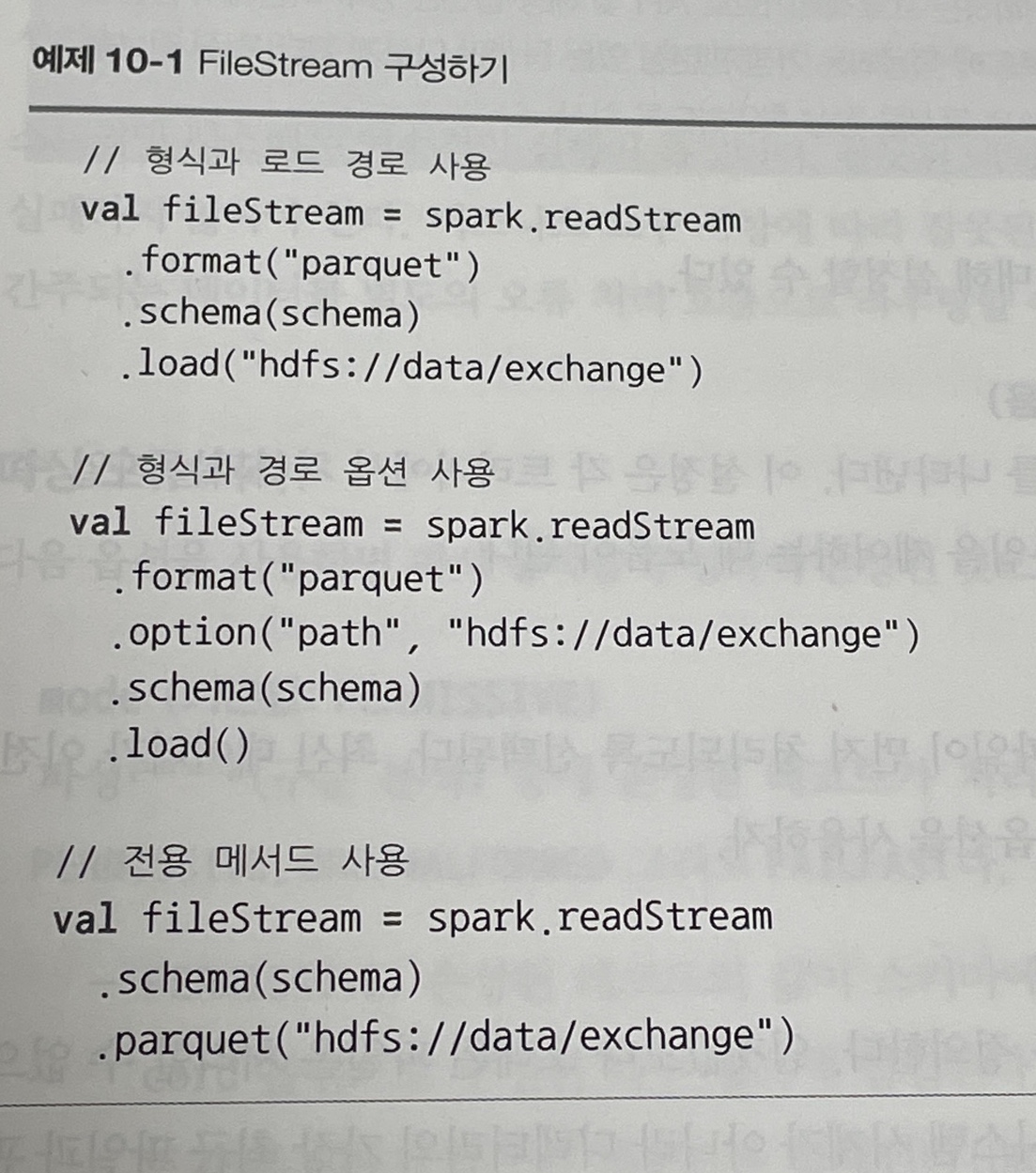
10.3 파일 소스
10.4 카프카 소스
10.5 소켓 소스
10.6 레이트 소스
CHAPTER 11 구조적 스트리밍 싱크
11.1 싱크의 이해
11.2 사용 가능한 싱크
11.3 파일 싱크
11.4 카프카 싱크
11.5 메모리 싱크
11.6 콘솔 싱크
11.7 foreach 싱크
CHAPTER 12 이벤트 시간 기반 스트림 처리
12.1 구조적 스트리밍에서의 이벤트 시간에 대한 이해
12.2 이벤트 시간의 사용
12.3 처리 시간
12.4 워터마크
12.5 시간 기반 윈도우 집계
12.6 레코드 중복 제거
12.7 요약
CHAPTER 13 고급 상태 기반 작업
13.1 예제: 차량 유지 보수 관리
13.2 상태 작동을 통한 그룹의 이해
13.3 MapGroupsWithState의 사용
13.4 FlatMapGroupsWithState 사용
13.5 요약
CHAPTER 14 구조적 스트리밍 애플리케이션 모니터링
14.1 스파크 메트릭 하위시스템
14.2 StreamingQuery 인스턴스
14.3 StreamingQueryListener 인터페이스
CHAPTER 15 실험 영역: 연속형 처리와 머신러닝
15.1 연속형 처리
15.2 머신러닝
[Part 3 스파크 스트리밍]
CHAPTER 16 스파크 스트리밍 소개
16.1 DStream 추상화
16.2 스파크 스트리밍 애플리케이션의 구조
16.3 요약
CHAPTER 17 스파크 스트리밍 프로그래밍 모델
17.1 DStream의 기본 추상화로서의 RDD
17.2 DStream 변환의 이해
17.3 요소 중심의 DStream 변환
17.4 RDD 중심의 DStream 변환
17.5 계산 변환
17.6 구조 변경 변환
17.7 요약
CHAPTER 18 스파크 스트리밍 실행 모델
18.1 대량 동기화 아키텍처
18.2 리시버 모델
18.3 리시버가 없는 모델 또는 직접 모델
18.4 요약
CHAPTER 19 스파크 스트리밍 소스
19.1 소스의 유형
19.2 일반적으로 사용되는 소스
19.3 파일 소스
19.4 큐 소스
19.5 소켓 소스
19.6 카프카 소스
19.7 더 많은 소스를 찾을 수 있는 곳
CHAPTER 20 스파크 스트리밍 싱크
20.1 출력 연산
20.2 내장형 출력 연산
20.3 프로그래밍 가능한 싱크로서 foreachRDD 사용하기
20.4 서드파티 출력 연산
CHAPTER 21 시간 기반 스트림 처리
21.1 윈도우 집계
21.2 텀블링 윈도우
21.3 슬라이딩 윈도우
21.4 윈도우 사용과 더 긴 배치 간격 사용
21.5 윈도우 기반 감소
21.6 가역 윈도우 집계
21.7 슬라이싱 스트림
21.8 요약
CHAPTER 22 임의 상태 기반 스트리밍 연산
22.1 스트림 규모의 상태 기반
22.2 updateStateByKey
22.3 updateStateByKey의 한계
22.4 mapwithState를 사용한 상태 기반 연산 소개
22.5 mapWithState 사용하기
22.6 mapWithState를 사용한 이벤트 시간 스트림 계산
CHAPTER 23 스파크 SQL로 작업하기
23.1 스파크 SQL
23.2 스파크 스트리밍에서 스파크 SQL 함수에 접근하기
23.3 유휴 데이터 처리
23.4 조인 최적화
23.5 스트리밍 애플리케이션에서 참조 데이터셋 업데이트하기
23.6 요약
CHAPTER 24 체크포인팅
24.1 체크포인트 사용법의 이해
24.2 DStream 체크포인팅
24.3 체크포인트에서 복구
24.4 체크포인팅 비용
24.5 체크포인트 튜닝
CHAPTER 25 스파크 스트리밍 모니터링
25.1 스트리밍 UI
25.2 스트리밍 UI를 이용하여 잡 성능 이해하기
25.3 REST API 모니터링
25.4 지표 하위시스템
25.5 내부 이벤트 버스
25.6 요약
CHAPTER 26 성능 튜닝
26.1 스파크 스트리밍의 성능 밸런스
26.2 잡의 성능에 영향을 미치는 외부 요소
26.3 성능을 향상시킬 수 있는 방법
26.4 배치 간격 조정하기
26.5 고정 속도 스로틀링을 통한 데이터 수신 제한
26.6 백프레셔
26.7 동적 스로틀링
26.8 캐싱
26.9 추측적 실행
[Part 4 고급 스파크 스트리밍 기술]
CHAPTER 27 스트리밍 근사 및 샘플링 알고리즘
27.1 정확성, 실시간 그리고 빅데이터
27.2 정확성, 실시간 그리고 빅데이터 삼각형
27.3 근사 알고리즘
27.4 해싱과 스케칭: 소개
27.5 고유 요소 계산: HyperLogLog
27.6 카운팅 요소 빈도: 최소 스케치 카운트
27.7 순위와 분위수: T-다이제스트
27.8 요소 수 줄이기: 샘플링
CHAPTER 28 실시간 머신러닝
28.1 나이브 베이즈를 이용한 스트리밍 분류
28.2 의사 결정 트리 소개
28.3 Hoeffding 트리
28.4 온라인 K-평균을 사용한 스트리밍 클러스터링
[Part 5 아파치 스파크를 넘어]
CHAPTER 29 기타 분산 실시간 스트림 처리 시스템
29.1 아파치 스톰
29.2 아파치 플링크
29.3 카프카 스트림
29.4 클라우드에서
CHAPTER 30 미리 살펴보기
30.1 연결 상태 유지
30.2 밋업에 참석하기
30.3 아파치 스파크 프로젝트에 기여하기
아파치 스파크를 사용한 스트림 처리에 오신 것을 환영합니다
2009년 캘리포니아대학교 버클리캠퍼스U의 마테이 자하리아가 처음 시작한 이래 아파치 스파크 프로젝트와 아파치 스파크를 사용한 스트림 처리가 얼마나 많은 성과를 거두었는지 살펴보는 것은 매우 흥미로운 일입니다. 아파치 스파크는 빅데이터 처리를 위한 최초의 통합 엔진으로 출발하여 모든 빅데이터의 실질적인 표준으로 성장했습니다.
이 책은 스트림 처리 엔진으로서 아파치 스파크의 개념, 도구 및 기능에 대해 가장 잘 소개하고 있습니다. 이 책은 먼저 최신 분산 처리를 이해하는 데 필요한 핵심 스파크 개념을 소개합니다. 그런 다음 다른 스트림 처리 아키텍처와 그 사이의 근본적인 아키텍처적인 절충안을 탐구합니다. 마지막으로 아파치 스파크의 구조적 스트리밍으로 분산 스트리밍 애플리케이션을 쉽게 구현하는 방법을 보여줍니다. 또한 레거시 커넥터를 사용하여 스트리밍 애플리케이션을 구축하기 위한 이전 스파크 스트리밍(일명 DStream) API도 다룹니다.
전체적으로 이 책은 아파치 스파크를 사용하여 스트리밍 애플리케이션을 구축하고 운영하기 위해 알아야 할 모든 것을 다룹니다! 우리는 당신이 무엇을 만들어낼지 기대하겠습니다!
오탈자 등록