회귀 분석 : 전복의 고리 수 추정 신경망
전복 나이를 알아내는 데 이용하는 껍질의 고리 수를 추정하는 회귀 분석 신경망을 만들어보자. 신경망은 단층 퍼셉트론으로 구현하며, 캐글의 아발로니 데이터셋을 활용한다.
실습을 하기에 앞서 아발로니 데이터셋을 내려받아두자.
이 장에서 다루는 내용은 다음과 같다. 그 중에 1번과 2번을 소개해 드리겠다.
1.1 단층 퍼셉트론 신경망 구조
단층 퍼셉트론은 다음 그림처럼 일련의 퍼셉트론을 한 줄로 배치하여 입력 벡터 하나로부터 출력 벡터 하나를 단번에 얻어내는 가장 기본적인 신경망 구조다.
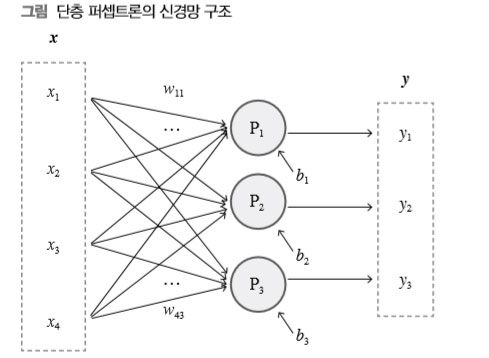
입력 벡터로부터 출력 벡터를 얻어내려면 출력 벡터의 크기, 즉 출력 벡터가 담고 있어야 할 스 칼라 성분의 수만큼의 퍼셉트론이 필요하다. 그림에서 P1, P2, P3은 크기 3의 출력 벡터를 만들 어내기 위한 퍼셉트론들을 나타내며 이들 퍼셉트론 사이에는 어떤 연결도 없어서 서로 영향을 주고받을 수 없다. 이들 퍼셉트론은 저마다의 가중치 벡터와 편향값을 이용하여 입력 벡터 x로 부터 출력 벡터 y를 도출한다.
예를 들어 첫 번째 퍼셉트론 P1은 가중치 벡터 (w11, w21, w31, w41)과 편향값 b1을 이용해 입 력 x1, x2, x3, x4로부터 y1=x1w11+x2w21+x3w31+x4w41+b1을 계산해 출력하며 P2나 P3도 같은 방식으로 y2와 y3을 계산한다.
이처럼 단층 퍼셉트론에서 퍼셉트론들은 입력 벡터만 공유할 뿐 각자의 가중치 벡터와 편향값에 따라 각자의 방식으로 독립적인 정보를 따로따로 생산한다. 한편 이들 퍼셉트론의 가중치 벡터들을 한데 모은 것이 가중치 행렬 W이고 편항값들을 한데 모은 것이 편향 벡터 b이다. 그리고 실제 퍼셉트론들의 계산은 가중치 행렬과 편향 벡터를 이용하여 한꺼번에 처리하게 된다.
참고로 학습 과정 중에 끊임없이 변경되어 가면서 퍼셉트론의 동작 특성을 결정하는 값들을 파라미터parameter라고 한다. 가중치와 편향은 대표적인 파라미터다. 딥러닝 학습 목표는 한마디로 문제 풀이에 적합한 파라미터값의 조합을 구하는 것이다. 파라미터를 모델 파라미터model parameter라고 부르기도 하는데 이는 뒤에 소개할 하이퍼파라미터hyperparameter와 확실하게 구분하는 용도로 사용한다.
퍼셉트론들끼리 서로 영향을 주고받을 수 없기 때문에 단층 퍼셉트론 신경망으로 높은 수준의 문제 해결 능력을 기대하기 어렵다. 이에 따라 입력을 일차 처리하여 그 결과를 최종 출력을 생성할 퍼셉트론 열에 제공하는 새로운 퍼셉트론 열들을 신경망에 추가하기도 한다. 딥러닝에서는 퍼셉트론 열을 계층layer이라고 부르는데 최종적으로 출력을 생성하는 계층을 출력 계층이라고 한다. 출력 계층 앞에서 입력을 처리하여 그 결과를 출력 계층에 전달하는 계층을 은닉 계층이라고 부른다.
따라서 단층 퍼셉트론은 은닉 계층 없이 출력 계층 하나만으로 구성되는 가장 간단한 신경망 구조다. 출력 계층 앞에 은닉 계층을 갖는 다층 퍼셉트론은 3장에서 살펴본다.
|
입력 계층에 대하여 입력 벡터 x를 제공하는 부분을 입력 계층이라고 부르는 경우가 있는데 논란의 여지가 있다. 입력 벡터는 독립적인 퍼셉트론 열에서 생산되는 것이 아니라 학습 데이터로부터 얻어져 직접 출 력 계층 혹은 은닉 계층에 제공되기 때문이다.인간의 시각에서는 망막의 빛수용체에서 신호를 전달받는 뉴런 세포들을 입력 계층으로 볼 수 있다. 하지만 인공 신경망들에는 그런 퍼셉트론 계층이 필요 없다. 이안 굿펠로, 요슈아 벤지오, 에런 쿠빌이 함께 저술한 『심층학습Deep Learning』(제이펍, 2018)1에서는 입력 계층input layer을 전혀 언급하지 않는다. 이 책에서도 입력 계층의 실체를 인정하지 않으며 앞으로 다시 언급하지 않을 것이다. |
단층 퍼셉트론은 비록 간단한 구조지만 여러 고급 신경망 구조의 기본 요소다. 고급 신경망 안에서는 여러 계층이 다양한 방식으로 연결된다. 이때 각 계층이 단층 퍼셉트론 혹은 단층 퍼셉트론을 변형시킨 구조를 갖는다. 따라서 단층 퍼셉트론의 동작과 학습 과정을 이해하는 것은 고급 신경망의 복합 구조를 이해하는 바탕이 된다.
1.2 텐서 연산과 미니배치의 활용
딥러닝 프로그래밍에서 텐서의 이해와 활용은 대단히 중요하다. 텐서를 엄밀하게 정의하기란 쉽지 않지만 딥러닝에서는 다차원 숫자 배열 정도로만 이해해도 큰 문제가 없다. 0차원 스칼라, 1차원 벡터, 2차원 행렬이 모두 텐서이며, 3차원 이상의 숫자 배열 역시 텐서다.
딥러닝에서 텐서가 중요한 이유는 같은 문제라도 반복문 대신 텐서를 이용해 처리하는 편이 프로그램도 간단하고 처리 속도도 훨씬 빠르기 때문이다. 이는 파이썬 인터프리터가 반복문보다 텐서 연산을 더 효율적으로 처리할 수 있기 때문이며, 특히 병렬 수치 연산을 지원하는 GPU 이용 환경에서 속도 차이는 더욱 커진다.
일반적으로 딥러닝에서는 신경망이 여러 데이터를 한꺼번에 처리하는데 이를 미니배치minibatch라고 한다. 아래의 그림은 ⓐ 퍼셉트론 하나의 동작 방식, ⓑ 입력 데이터 하나에 대한 단층 퍼셉트론의 동작 방식, ⓒ 입력이 여럿인 미니배치에 대한 단층 퍼셉트론의 동작 방식을 차례로 나타낸 것 이다.
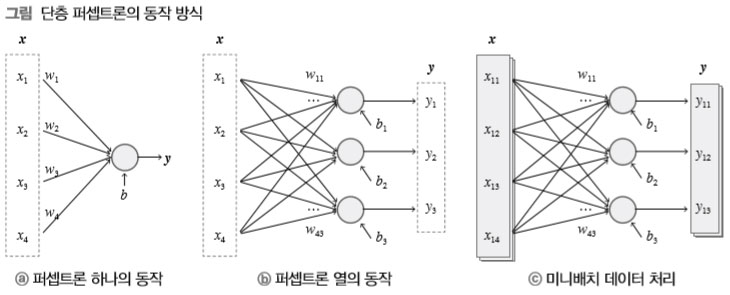
단층 퍼셉트론은 보통 ⓒ 형태다. ⓐ, ⓑ는 단지 ⓒ의 작동 방식을 단계적으로 이해하는 용도로 간단화한 것뿐이다. 이어지는 설명에 언급된 수식에서 소문자 굵은 글씨체는 벡터, 대문자 굵은 글씨체는 행렬을 나타낸다.
그림 ⓐ는 퍼셉트론 하나가 동작하는 방식이다. 이 퍼셉트론은 가중치 벡터 w=(w1,...,wn)와 스칼라 편향 b를 이용해 입력 벡터 x=(x1,...,xn)로부터 스칼라 출력 y=x1w1+⋯+xnwn+b=xw+b를 계산한다. 이때 반복문을 이용해 xiwi들을 모두 계산하고 합산해서 y를 구할 수도 있지만 그보다는 벡터의 내적 연산을 이용해 xw를 단번에 계산하는 편이 훨씬 간단하고 빠르다. 한편 입력 성분의 일차식으로 표현되는 이런 계산 과정을 선형 연산이라고 하며, 일차식으로 나타낼 수 없는 계산 과정을 비선형 연산이라 한다. 2장부터는 신경망 출력 처 리에 비선형 함수를, 4장부터는 퍼셉트론 안에도 활성화 함수라는 이름으로 비선형 함수를 이 용한다. 하지만 이번 장에서 다루는 회귀 분석 문제 풀이에 사용하는 단층 퍼셉트론에서는 아직 비선형 함수를 이용하지 않는다.
그림 ⓑ는 단층 퍼셉트론을 구성하는 일련의 퍼셉트론들이 데이터 하나를 처리할 때의 동작 방식을 나타낸다. 퍼셉트론이 여럿이니 가중치는 가중치 벡터들이 퍼셉트론 수만큼 모인 가 중치 행렬 W가 되며 편향 역시 벡터 b가 된다. 이때 출력 벡터 y를 구성하는 yi값들은 각각 yi=x1wi1+⋯+xnwin+b=xwi+bi로 구해지는데 이를 한꺼번에 표현하면 y=xW+b다.
역시 퍼셉트론 하나의 동작을 반복문으로 처리하기보다는 y=xW+b 식을 이용하여 벡터와 행렬의 연산 형태로 전체 퍼셉트론을 한꺼번에 처리하는 편이 훨씬 효율적이다.
그림 ⓒ는 미니배치 처리에서의 단층 퍼셉트론의 동작 방식을 나타낸다. 데이터가 여러 개 모 여서 입력 행렬 X와 출력 행렬 Y가 될 뿐 ⓑ에서와 같은 일련의 퍼셉트론들이 각 데이터에 공 통적으로 적용되어 yj=xjW+b를 계산하는 것이다. 따라서 가중치 행렬 W와 편향 벡터 b가 그대로 이용된다. 이 미니배치 처리는 Y=XW+b의 식으로 요약 가능하며 역시 반복문으로 ⓐ나 ⓑ의 동작을 반복하기보다 행렬 연산을 이용하여 단번에 계산하는 편이 간단하고 효율적이다.
예제의 구현 과정에서 거듭 살펴보겠지만 딥러닝 프로그램의 효율을 높이려면 최대한 반복문 사용을 피하고 텐서 연산을 이용해 처리하는 것이 중요하다는 점을 명심해두어야 한다. 미니배치는 모든 학습 데이터를 한꺼번에 일괄처리하는 배치 작업은 아니지만 그렇다고 해서 데이터를 하나씩 다루지도 않는다. 배치 작업보다 상대적으로 작은 단위로 처리하는 일괄처리라서 미니배치라는 이름이 붙었다. 미니배치는 데이터 처리의 효율을 높여주며 개별 학습 데이터의 특징을 무시하지 않으면서도 특징에 너무 휘둘리지 않게 해주어서 유용하다.
학습 데이터 전체에 대한 한 차례 처리를 에포크epoch(에폭, 이폭으로도 부른다)라고 한다. 딥러닝에서는 에포크 수나 미니배치 크기처럼 학습 과정에서 변경되지 않으면서 신경망 구조나 학습 결과에 영향을 미치는 고려 요인들을 하이퍼파라미터hyper parameter라고 한다. 하이퍼파라미터값은 신경망 설계자가 학습 전에 미리 정해주어야 하는 값이며 학습 결과에 큰 영향을 미치는 경우가 많다. 따라서 신경망 설계자는 문제 유형, 신경망 구조, 데이터양, 학습 결과 등을 종합적으로 살펴보며 하이퍼파라미터값들을 잘 조절해야 한다.
파이썬 날코딩으로 알고 짜는 딥러닝 자세히 보러가기 ▽

이전 글 : 프로그래밍 면접 - 기술 이력서 쓰는 방법
다음 글 : 왜 자연어 처리는 어려울까?

최신 콘텐츠