![]() Ben Lorica
Ben Lorica
2019-08-20
![]() 14.4K
14.4K
기업은 기존의 제품 및 서비스를 기반으로 하거나 기존 모델 및 알고리즘을 현대화함으로서 성공적으로 머신러닝을 채택했습니다.
이 글에서, 저는 올해 초에 런던에서 열린 Stara 데이터 컨퍼런스에서 배부했던 키노트의 슬라이드와 노트들을 공유합니다. 최근 기계학습 도입에 대한 조사 결과를 강조하고, 더 나아가 기업 내 데이터 및 머신러닝(ML)의 최근 동향을 설명하고자 합니다. 지금은 많은 기업들이 이미 머신러닝을 사용하기 시작했다는 많은 징후가 있기 때문에 기업 활동을 평가하기에 좋은 시기입니다. 예를 들어, 11,000명 이상의 사람들이 참여했던 2018년 7월 설문조사에서 우리는 기업들이 적극적으로 참여(기업 중 51%는 이미 현업에서 머신러닝 모델들을 보유하고 있다)하고 있다는 사실을 알 수 있었습니다.
인공지능에 대한 모든 과대 광고는 여러분에게 익숙하지 않은 데이터 유형과 관련된 사례에 뛰어들고 싶은 충동을 일으킬 수 있습니다. 우리는 머신러닝을 성공적으로 채택한 기업들이 기존 데이터 산출물과 서비스를 구축하거나, 기존 모델과 알고리즘을 최신화한다는 것을 알 수 있었습니다. 다음은 기업들이 머신러닝을 도입할 때 사용하는 일반적인 몇 가지 방법입니다.
딥러닝은 2011/2012년에 음성과 컴퓨터 비전에서의 기록 설정 모델로 인해 재조명된 머신러닝의 특정 형태로 간주됩니다. 우리가 음성과 컴퓨터 비전과 관련된 대단한 발견을 하는 동안, 기업들은 기존의 모델과 알고리즘을 확장하거나 대체하기 위한 딥러닝을 사용하기 시작했습니다. 대표적인 예로 상태 중심 접근방식에서 텐서플로우로 전환된 구글의 기계 번역 시스템이 있습니다. 우리 컨퍼런스에서, 우리는 시계열과 자연어 처리(조직들이 이미 기존에 해결책을 가지고 있을 가능성이 있고, 딥러닝이 어떤 가능성을 보이기 시작하는 두 가지 영역)를 위한 딥러닝 튜토리얼 및 교육 세션에 강한 관심을 보이고 있습니다.
머신러닝은 더 많은 제품과 시스템에서 대두되고 있을 뿐 아니라, 응용 프로그램 자체가 구축되는 방식을 바꿀 것입니다. 개발자들은 점점 더 머신러닝 요소가 포함된 소프트웨어를 개발하게 될 것입니다. 따라서 많은 개발자들은 데이터를 조직하고, 모델을 학습하고, 모델의 결과를 분석해야 할 것입니다. 이 말인 즉슨, 우리는 여전히 머신러닝의 실험적 단계에 있습니다 : 우리는 빅데이터, 빅 모델, 그리고 빅 컴퓨팅이 필요합니다.
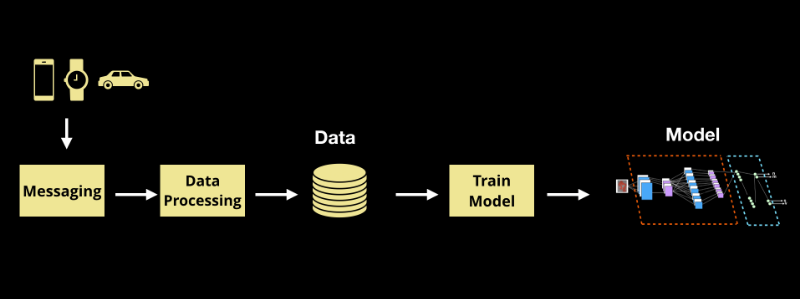
Figure 1. A typical data pipeline for machine learning. Source: O'Reilly.
어쨌든, 딥러닝 모델은 데이터 과학자들이 선호하는 이전의 알고리즘보다 훨씬 더 많은 데이터가 필요합니다. 데이터는 머신러닝 응용 프로그램의 핵심이자 데이터를 풍성하게 하고, 정제되게 하며 사용 가능한 형태로 머신러닝 학습을 유지하는 핵심이 될 것입니다.
머신러닝의 중요성이 커지고 있는 것을 확인할 목적으로, 우리는 최근에 3,200명 이상의 응답자를 유치한 데이터 인프라 조사를 완료했습니다. 우리의 목표는 두 가지였습니다. 첫째로 사람들이 어떤 툴과 플랫폼을 사용하는지, 둘째로 기업이 그들의 머신러닝 추진을 지속하는 데 필요한 기초적인 툴을 구축하고 있는지 알아내는 것이었습니다. 대다수의 응답자들이 오픈소스 툴(아파티 스파크, 카프카, 텐서플로우, 파이토치 등)과 클라우드 관리 서비스를 사용하고 있다고 응답했습니다.
우리가 한 주요 질문 중 하나는 “현재 무엇을 조직하고 있고 발전시키고 있는가?” 였습니다.
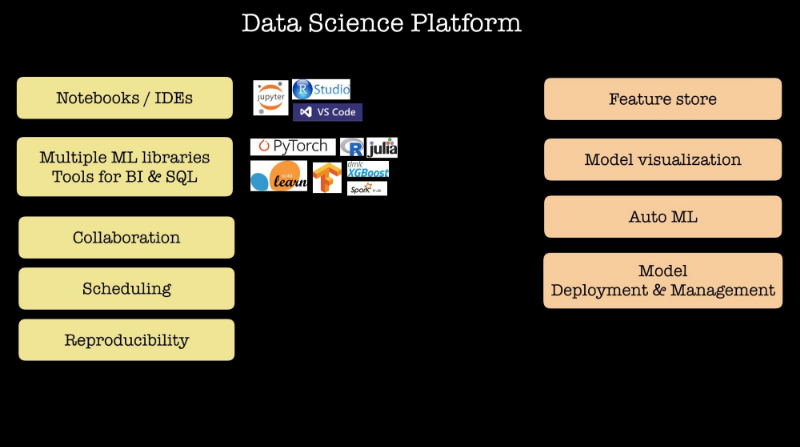
Figure 2. Key features of many data science platforms. Source: O'Reilly.
클라우드는 어떤가요? 최근 설문 조사에서는 대다수가 이미 데이터 인프라의 일부에 대해 공용 클라우드를 사용하고 있으며, 3분의 1 이상이 서버리스로 사용하고 있는 것으로 나타났습니다. 우리는 최근 인공지능과 데이터 응용 프로그램에서의 서버리스의 역할에 대한 애브너 브레이브맨의 강연의 뒤를 이어 에릭 조나스가 최근 UC Berkeley의 서버리스에 대한 결해를 정리한 논문에서 언급한 내용을 포함한 컨퍼런스에서 서버리스(Serverless)에 대한 많은 교육 세션과 튜토리얼, 그리고 토론을 가졌습니다.
기업들은 이제 막 머신러닝 응용 프로그램을 구축하기 시작했으며, 저는 다음과 같은 몇 가지의 이유로 머신러닝의 사용이 향후 몇 년간 계속 증가할 것으로 확신합니다.
머신러닝이 계속해서 회사 내에서 발전할 것이라는 몇 가지 초기 지표가 있는데, 두 가지 모두 머신러닝을 “생산”하는 데 관심을 가지는 기업의 수가 증가하고 있다는 것을 보여줍니다. 첫째, 우리가 언론에서 데이터 과학자들에 대한 많은 기사를 읽는 동안, 몇 년 전에 머신러닝 생산에 전념하는 새 포지션이 등장하기 시작했습니다.
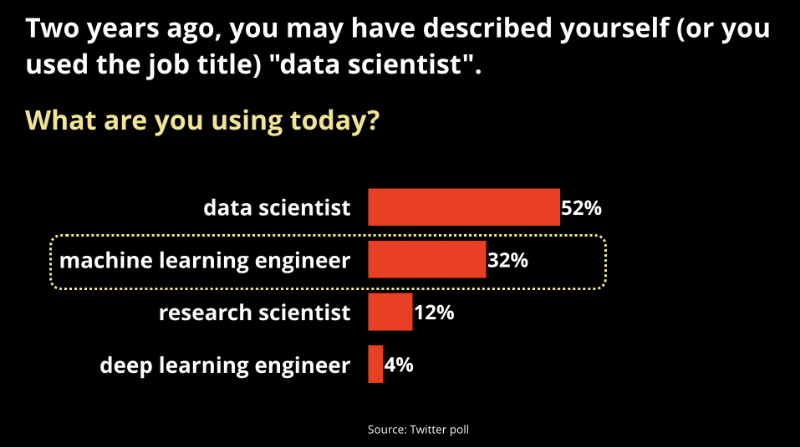
Figure 3. Data results from a Twitter poll. Source: O'Reilly.
머신러닝 엔지니어는 데이터 과학과 데브옵스 그 사이에 해당합니다. 그들은 데이터 과학자들보다 더 높은 급여를 받는 경향이 있고, 일반적으로 더 강력한 기술 및 프로그래밍 기술을 보유하고 있습니다.저의 트위터 여론조사 결과로 미루어 보건대, 데이터 과학자들이 이 새로운 직업의 타이틀로 “재브랜드화” 하고 있다는 초기 징후가 있는 것으로 보입니다.

Figure 4. Model development tools like MLflow are catching on. Source: O'Reilly.
MLflow같은 새 프로젝트의 인력을 살펴볼 때, 머신러닝에 대한 관심이 증가하고 있다는 또 다른 신호(출시한 지 불과 10개월 만에 우리는 이미 많은 회사들로부터 많은 관심을 받고 있습니다)가 있습니다. 머신러닝 플로우의 일반적인 활용 사례는 실험 추적 및 관리입니다. - MLflow 전에는, 이것을 위한 좋은 오픈소스 툴이 없었습니다. MLflow와 Kubeflow와 같은 프로젝트(comet.ml과 Verta.AI 같은 회사의 제품)를 통해 머신러닝의 발전으로서 회사가 더 관리하기 쉽도록 했습니다.
MLflow는 흥미로운 새 툴이지만, 이것은 모델 개발에 초점을 맞추고 있습니다. 머신러닝 연구가 조직의 여러 부분으로 확장됨에 따라, 다른 전문적인 도구가 필요하다는 것이 명확해집니다. 머신러닝을 위한 데이터 플랫폼과 인프라를 구축한 많은 회사들과 관련하여 툴 체인 설계 시 고려해야 할 몇 가지 중요한 요소가 대두됩니다.

Figure 5. Important considerations when designing your ML platform. Source: O'Reilly.
데이터가 전문화된 도구(데이터 거버넌트 솔루션 및 데이터 카탈로그 포함)가 필요한 자산인 것처럼 모델도 관리 및 보호가 필요한 귀한 자산입니다. 모델 거버넌스와 모델 운영(기계 학습 민주화의 다음 큰 단계는 이것을 보다 더 관리하기 쉽게 하고 있습니다)을 위한 도구들 또한 점점 더 중요해질 것입니다. 기계 학습 민간화의 다음 큰 단계는 이것을 보다 더 관리하기 쉽게 하고 있습니다. 모델 거버넌스 및 모델 운영에는 다음과 같은 항목이 포함된 솔루션이 필요합니다.
기업들은 머신러닝의 사용에 따라 고려해야 할 많고 중요한 사항들이 있다는 것을 배우고 있습니다. 다행히도, 연구 집단은 공정성, 설명설, 안전성과 신뢰성, 특히 보안과 프라이버시를 포함한 머신러닝이 제시하는 몇 가지 중요한 과제를 해결하기 위한 기술과 툴을 출시하기 시작했습니다. 머신러닝은 종종 사용자와 상호작용하며 영향을 미치기 때문에 기업들은 머신러닝을 책임감 있게 적용할 수 있는 프로세스를 적재할 필요가 있을 뿐만 아니라, 특히 일이 잘못되었을 때 감독권을 유지할 수 있는 기초 기술을 구축할 필요가 있습니다. 위에서 언급한 데이터 거버넌스, 데이터 라인, 모델 거버넌스 등 모든 기술은 이러한 위험을 관리하는 데 유용할 것입니다. 특히 감사와 테스트 머신러닝 학습 시스템은 위에서 설명했던 많은 툴들에 의존할 것입니다.
이론 뿐 아니라 실제로, 위험성과 고려해야 할 사항이 있습니다. 이러한 기본 도구들은 점점 더 필수적이게 되어 더 이상 선택적이지 않을 것입니다. 예를 들어, 최근의 DLA Piper 조사는 규제 당국에 보고된 GDPR 위반 추정치(2019년 2월 현재 59,000건 이상의 개인 데이터 위반)을 보고했습니다.
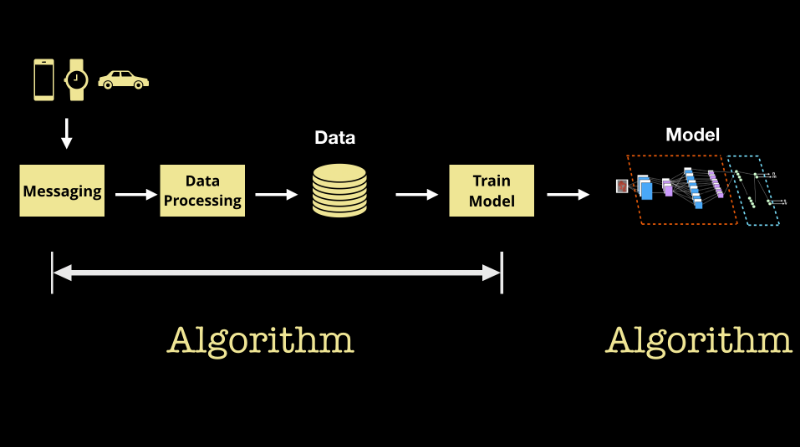
Figure 6. Machine learning involves a series of interrelated algorithms. Source: O'Reilly.
우리가 머신러닝을 적용하는 “모델”이나 “알고리즘”을 생성하는 것으로 생각하는 경향이 있지만, 실제로 다음 두 가지 알고리즘을 추적하기 위해 머신러닝 시스템을 감사하는 것은 아주 어려울 수 있습니다. :
따라서, 머신러닝을 관리하는 것은 일련의 상호 연관 알고리즘을 관리할 수 있는 일련의 툴을 개발하는 것을 위미합니다. 앞에서 설명한 조사 결과에 기반하여 기업들은 책임 있는 머신러닝 관행을 유지하는 데 중요한 중요한 기초 기술(데이터 통합 및 ETL, 데이터 거버넌스 및 데이터 카탈로그, 데이터 라인, 모델 개발 및 모델 거버넌스 등)을 구축하기 시작하고 있습니다.
하지만 특히 많은 IT, 소프트웨어 및 클라우드 솔루션(“실행을 유지하는 것”의 필수 작업을 관리해야 함에도 불구하고)을 해결해야 하는 기업 내에서 머신러닝의 사용이 증가함에 때라 과제는 여전히 남아 있습니다. 좋은 소식은, 기업들이 필수적인 기초 기술을 구축하거나 획득할 필요성을 인식하기 시작했다는 초기 지표가 있다는 것입니다.
*****
원문 : Becoming a machine learning company means investing in foundational technologies
번역 : 윤현진
![]() 0
0




댓글