2022년은 신종 코로나 바이러스가 기승을 부리는 가운데 AI 분야가 크게 진전한 한 해였습니다. 우리의 상상을 아득히 뛰어넘는 이미지를 AI가 만들어내기 시작한 것입니다. 대표적으로 스테이블 디퓨전Stable Diffusion, 미드저니Midjourney, DALL-E 등을 들 수 있습니다.
이미지 생성 AI는 다양한 분야에서 주목받고 다양한 목적으로 활용되고 있습니다. 눈여겨볼 점은 이들 AI의 배후에는 딥러닝을 통한 ‘생성 모델’ 기술이 활용되고 있다는 사실입니다. 다르게 말하면 2022년은 생성 모델에서 축적된 기술이 한꺼번에 꽃핀 해라고 할 수 있습니다.
이 책의 주제는 바로 이러한 생성 모델입니다. 생성 모델generative model이란 새로운 데이터를 생성하는 기술을 말합니다. 이 책은 생성 모델이라는 큰 틀에서 고전 모델부터 최첨단 기술까지를 폭넓게 다룹니다. 시작은 정규 분포와 최대 가능도 추정(MLE)과 같은 기본적인 내용입니다. 이어서 가우스 혼합 모델(GMM)과 기댓값 최대화 알고리즘(EM 알고리즘)을 배우고, 이후 딥러닝을 이용한 방법으로 넘어갑니다. 구체적으로 변이형 오토인코더(VAE), 계층형 VAE, 확산 모델을 차례로 만들면서 이론과 구현 방법을 모두 배웁니다.
확산 모델은 뛰어난 성능으로 생성 AI 분야에 혁명을 일으켰습니다. 이 책은 종착점인 확산 모델에 이르는 과정을 10단계로 나누어 설명합니다. 10단계의 과정은 하나의 이야기로 이어지며 각 단계마다 생성 모델에서 중요한 기술을 익히게 됩니다.
이 책은 생성 모델의 메커니즘을 가감 없이 설명합니다. 단순히 이미지나 결과를 전달하는 데 그치지 않고 ‘왜 그렇게 되는지’와 ‘어떻게 그 결과를 얻을 수 있는지’도 빼놓지 않았습니다. 이를 위해 수식을 세심하게 다루며 작은 부분까지 신경 썼습니다. 기술을 깊이 이해하려면 결국은 디테일한 부분까지 배워야 합니다. 하지만 다행히도 기술의 디테일에 재미난 요소들이 담겨 있습니다.
미적분학과 선형대수학 등의 수학 이론과 파이썬 기초를 알고 있다면 이 책을 읽기가 한결 수월할 것입니다. 아주 기본적인 내용만 이해하고 있어도 충분합니다. 특히 수학 이론은 책 안에서 차근차근 복습하면서 진행할 수 있도록 구성했습니다. 어려운 수식이 가끔 등장하지만 건너뛰어도 책 전체를 이해하는 데는 문제가 없도록 꾸몄습니다.
이것이 이 책의 큰 틀이자 줄거리입니다. 이러한 여정에는 이 책만의 특징과 재미가 가득 담겨 있습니다. 그래서 먼저 큰 흐름을 파악할 수 있도록 전체 내용을 요약해 소개하겠습니다. 자세한 내용은 책 본문에서 차근차근 알아봅니다(세세한 부분에도 재미가 있으니 기대해주세요). 지금은 큰 흐름에만 집중합시다. 중간에 모르는 용어가 나올 수 있지만 책 본문을 읽다 보면 자연스럽게 알게 될 것입니다.
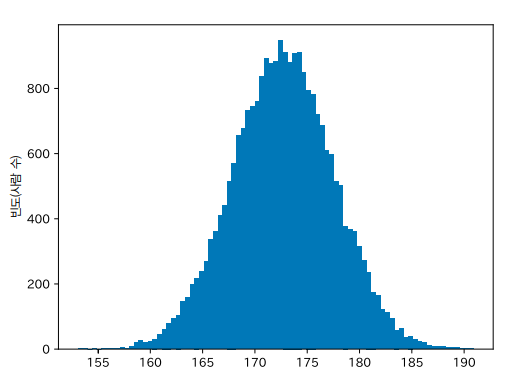
나이가 같은 남성 집단이 있습니다. 다음 그림은 이 집단의 키 분포입니다. 좌우 대칭인 산 모양이죠. 이런 형태를 ‘종 모양’이라고도 합니다. 생성 모델의 목표는 이러한 분포를 수학적으로 표현하는 것입니다.
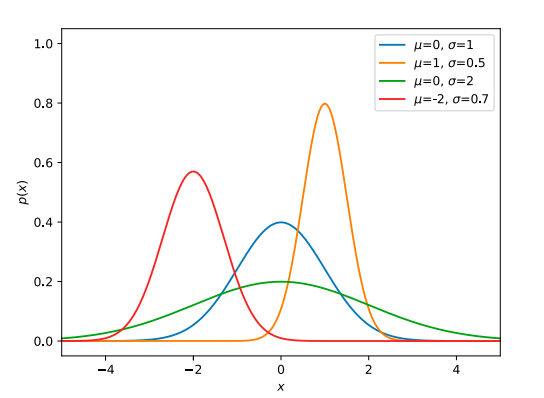
정규 분포는 종 모양 곡선으로 표현되는 확률 분포입니다. 세상에는 정규 분포로 표현할 수 있는 대상이 아주 많습니다. 방금 보았듯이 키 분포도 정규 분포로 표현할 수 있습니다. 정규 분포의 형태는 평균(n)과 표준 편차(v )라는 두 매개변수에 의해 결정됩니다.
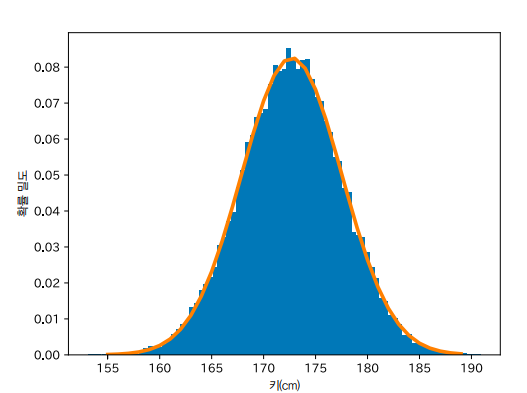
정규 분포로 현상을 정확하게 표현하려면 정규 분포의 매개변수를 조율하여 형태를 데이터에 맞추는 작업(적합화fit)을 해야 합니다. 그 방법이 ‘최대 가능도 추정’입니다. 최대 가능도 추정은 어떤 데이터 x가 관측될 확률 p(x)를 가장 커지게 하는지 매개변수를 추정하는 기법입니다. 정규 분포의 최대 가능도 추정 값은 수식을 풀면 쉽게 구할 수 있습니다.
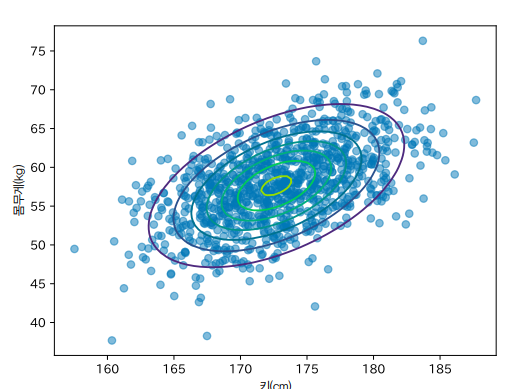
키는 1차원 데이터였습니다. 이번에는 ‘키와 몸무게’라는 2차원 데이터를 생각해봅시다. 이를 시각화한 것이 다음 그림입니다. 2차원 데이터도 똑같이 최대 가능도 추정을 이용해 최적의 매개변수를 추정할 수 있습니다. 그림의 등고선은 최대 가능도 추정 후의 2차원 정규 분포를 나타냅니다.
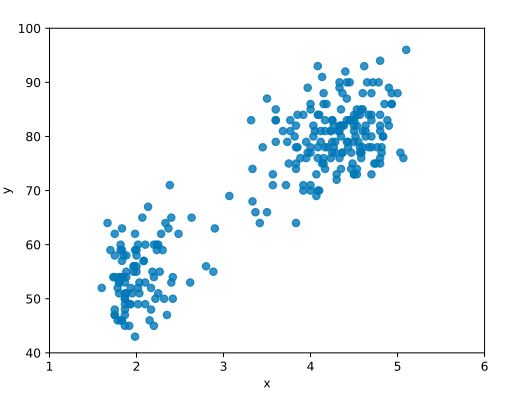
다음 대상은 ‘산이 두 개’인 샘플 데이터입니다. 이러한 형태의 데이터는 정규 분포 하나로는 표현할 수 없습니다. 그래서 등장한 것이 ‘가우스 혼합 모델(GMM)’입니다. 가우스 혼합 모델은 정규 분포 여러 개를 조합한 기법입니다. 따라서 산이 두 개여도 표현할 수 있습니다.
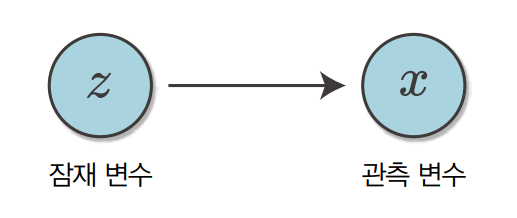
두 개의 산을 표현할 때는 데이터가 어느 산에 속하는지 나타내는 ‘잠재 변수’를 사용합니다. 잠재 변수란 직접 관찰할 수 없는 변수입니다. 한편 관찰 가능한 데이터는 ‘관측 변수’라고 합니다. 다음 그림은 잠재 변수 z로부터 관측 변수 x가 생성되는 관계를 나타냅니다.
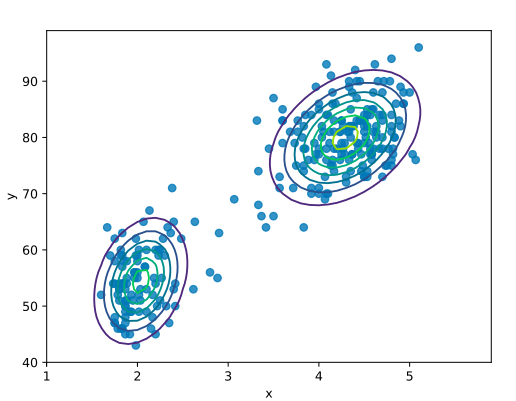
가우스 혼합 모델은 잠재 변수를 이용하기 때문에 모델(수식)이 복잡합니다. 따라서 정규 분포가 하나일 때처럼 수식을 푸는 방식으로는 최대 가능도 추정의 해를 구할 수 없습니다. 여기서 등장하는 것이 ‘EM 알고리즘(기댓값 최대화 알고리즘)’입니다. 이 알고리즘을 통해 최적의 매개변수를 추정할 수 있으며, 산이 두 개인 모델에도 정규 분포를 적용할 수 있습니다.
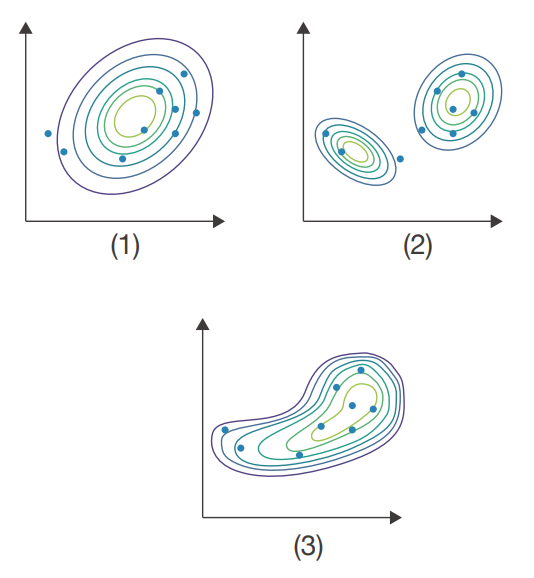
한 걸음 더 나아가 신경망을 도입해보겠습니다. 신경망을 이용하면 샘플 데이터에 더 잘 들어맞는 분포를 학습시킬 수 있습니다. 다음 그림에서 (1)은 하나의 정규 분포, (2)는 가우스 혼합 모델, (3)은 신경망을 도입한 ‘VAE(변이형 오토인코더)’ 모델입니다. 신경망을 도입하면 (3)처럼 복잡한 데이터까지도 표현해내는 유연한 모델을 얻을 수 있습니다.
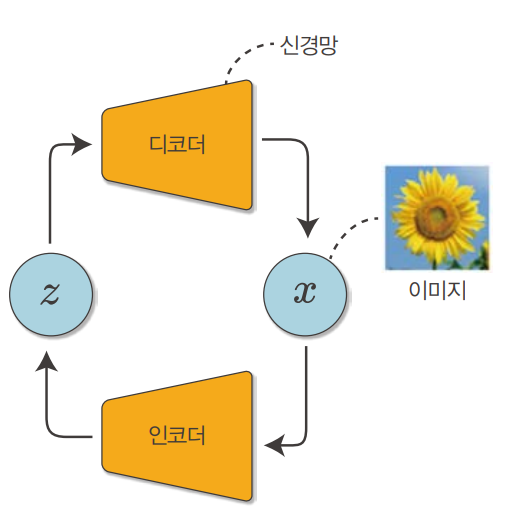
VAE도 가우스 혼합 모델과 마찬가지로 잠재 변수가 있는 모델입니다. 잠재 변수에서 관측 변수로 변환할 때 신경망을 사용하고(디코더), 그 반대로 변환할 때는 또 다른 신경망을 사용합니다(인코더). VAE의 학습 알고리즘은 EM 알고리즘을 발전시켜 이끌어낼 수 있습니다.
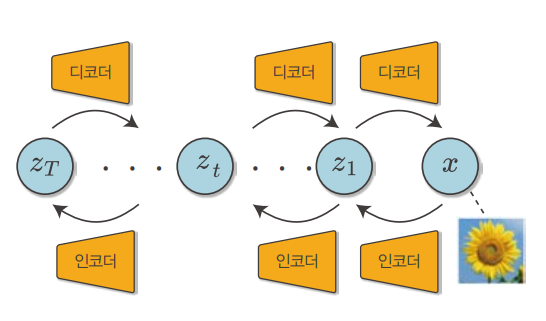
VAE는 자체로 상당히 복잡한 대상을 표현할 수 있지만 잠재 변수를 계층화하여 표현력을 더 개선할 수 있습니다. 이것이 바로 ‘계층형 VAE’입니다. 계층형 VAE란 VAE에 잠재 변수를 여러 개 도입한 모델입니다. 잠재 변수는 인접한 잠재 변수로부터만 영향을 받습니다. 이렇게 계층화를 거치면 더 복잡한 대상도 표현할 수 있습니다.
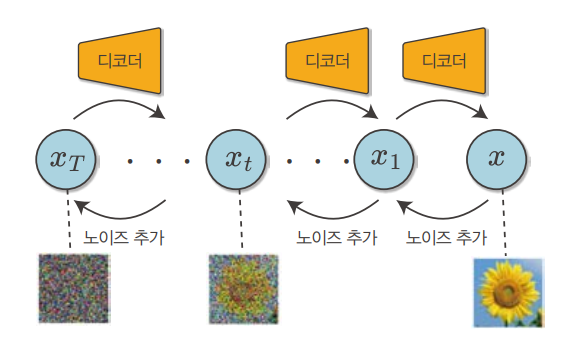
VAE의 계층을 늘리면 잠재 변수가 많아지는 만큼 신경망으로 처리할 것도 많아집니다. 따라서 처리 시간이 길어지는 문제와 매개변수 추정이 어려워지는 문제 등이 생깁니다. 이 문제들을 해결하기 위해 ‘관측 변수에서 잠재 변수로의 변환’을 단순한 ‘노이즈 추가’로 대체합니다(노이즈는 정규 분포에서 생성). 이 아이디어를 기점으로 확산 모델을 끄집어낼 수 있습니다. 노이즈를 추가하면서 데이터를 파괴하는 과정을 확산 과정이라고 합니다.
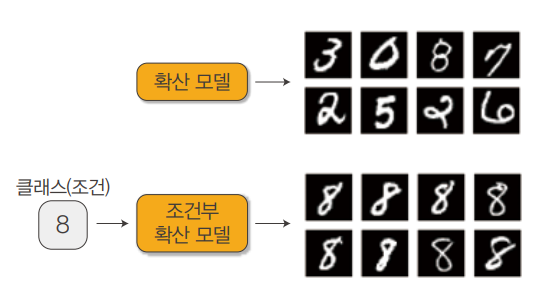
지금까지의 주제는 단순히 데이터 x의 확률 분포 p(x)를 모델링하는 것이었습니다. 하지만 어떤 조건 y가 주어졌을 때 x의 확률, 즉 수식으로는 p(x | y)로 표현되는 조건부 확률을 모델링해야 더 유용합니다. 예컨대 숫자 이미지를 생성한다면 조건 없는 확산 모델에서는 무작위로 아무 숫자나 생성합니다. 반면 조건부 확산 모델에서는 8과 같은 클래스를 조건으로 주어 원하는 숫자 이미지를 만들어낼 수 있습니다.
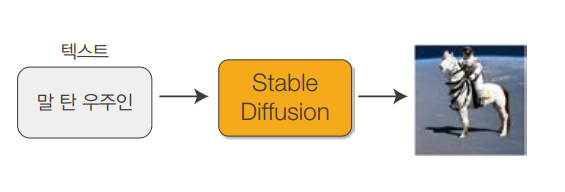
스테이블 디퓨전 같은 이미지 생성 AI도 조건부 확산 모델과 원리는 같습니다. 여기에 몇 가지 기법을 더해 다음 그림과 같은 고품질의 이미지를 생성합니다. 이 책에서는 스테이블 디퓨전을 비롯한 첨단 이미지 생성 AI에서 사용하는 기술들을 개괄적으로 살펴봅니다.

10단계로 알아보는 이미지 생성 모델의 원리!
생성형 AI와 함께하는 『밑바닥부터 시작하는 딥러닝 5』
이 책은 정규 분포와 최대 가능도 추정과 같은 기본 개념에서 출발하여 가우스 혼합 모델, 변이형 오토인코더(VAE), 계층형 VAE 그리고 확산 모델에 이르기까지 다양한 생성 모델을 설명합니다. 수식과 알고리즘을 꼼꼼하게 다루며 수학 이론과 파이썬 프로그래밍을 바탕으로 한 실제 구현 방법을 알려줍니다. 생성 모델을 이론뿐만 아니라 실습과 함께 명확하게 학습할 수 있습니다. 특히 확산 모델에 이르는 10단계의 과정을 하나의 스토리로 엮어 중요한 기술들을 서로 잇고 개선할 수 있도록 구성했습니다. 이 책과 함께 생성 모델을 밑바닥부터 시작해보세요.
이전 글 : 검색 시대의 종말 더 이상 AI 해자는 없다

최신 콘텐츠