1.2 왜 파이썬인가?

파이썬Python은 데이터 과학 분야를 위한 표준 프로그래밍 언어가 되어 가고 있습니다. 파이썬은 범용 프로그래밍 언어의 장점은 물론 매트랩MATLAB과 R 같은 특정 분야를 위한 스크립팅 언어의 편리함을 함께 갖췄습니다. 파이썬은 데이터 적재, 시각화, 통계, 자연어 처리, 이미지 처리등에 필요한 라이브러리들을 가지고 있습니다. 이러한 많은 도구가 데이터 과학자에게 아주 풍부하고 일반적인 그리고 또 특수한 기능들을 제공해줍니다. 곧 살펴보겠지만 파이썬의 장점 하나는 터미널이나 주피터 노트북Jupyter Notebook(옮긴이 주_ IPython 노트북에서 여러 언어를 포괄하는 프로젝트인 주피터 노트북으로 이름이 바뀌었고 IPython은 주피터 노트북의 파이썬 커널을 의미하게 되었습니다. Jupyter라는 이름은 줄리아(Julia), 파이썬(Python), R의 합성어이고 목성의 발음과 같아 과학자들과 천문학자들에 대한 경의가 담겨 있습니다. 주피터 노트북 로고의 가운데 큰 원은 목성을 의미하며 주위 3개의 작은 원은 1610년 목성의 위성 3개를 최초로 발견한 갈릴레오 갈릴레이를 기리는 의미입니다. https://jupyter.org/) 같은 도구로 대화하듯 프로그래밍할 수 있다는 점 입니다. 머신러닝과 데이터 분석은 데이터 주도 분석이라는 점에서 근본적으로 반복 작업입니다. 그래서 반복 작업을 빠르게 처리하고 손쉽게 조작할 수 있는 도구가 필수입니다.
범용 프로그래밍 언어로서 파이썬은 복잡한 그래픽 사용자 인터페이스(GUI)나 웹 서비스도 만들 수 있으며 기존 시스템과 통합하기도 좋습니다.
1.3 scikit-learn
오픈 소스인 scikit-learn싸이킷런은 자유롭게 사용하거나 배포할 수 있고, 누구나 소스 코드를 보고 실제로 어떻게 동작하는지 쉽게 확인할 수 있습니다. scikit-learn 프로젝트는 꾸준히 개발, 향상되고 있고 커뮤니티도 매우 활발합니다. 잘 알려진 머신러닝 알고리즘들은 물론 알고리즘을 설명한 풍부한 문서도 제공합니다. scikit-learn은 매우 인기가 높고 독보적인 파이썬 머신러닝 라이브러리입니다. 그래서 산업 현장이나 학계에도 널리 사용되고 많은 튜토리얼과 예제 코드를 온라인에서 쉽게 찾을 수 있습니다. 앞으로 보게 되겠지만 scikit-learn은 다른 파이썬의 과학 패키지들과도 잘 연동됩니다.
이 책을 읽으며 scikit-learn의 사용자 가이드를 같이 참고하면서 각 알고리즘에 대한 상세 내용과 다양한 옵션을 확인해보기 바랍니다. 온라인 문서는매우 자세한 내용을 포함하고 있으며 이 책은 그러한 상세 사항을 이해하는 데 필요한 머신러닝의 기초를 다루고 있습니다.
1.3.1 scikit-learn 설치
scikit-learn은 두 개의 다른 파이썬 패키지인 NumPy넘파이와 SciPy싸이파이를 사용합니다. 그래프를 그리려면 matplotlib맷플롯립을, 대화식으로 개발하려면 IPython아이파이썬과 주피터 노트북도 설치해야 합니다. 그래서 필요한 패키지들을 모아놓은 파이썬 배포판을 설치하는 방법을 권장합니다. 다음은 대표적인 배포판들입니다.
대용량 데이터 처리, 예측 분석, 과학 계산용 파이썬 배포판입니다. Anaconda아나콘다는 NumPy, SciPy, matplotlib, pandas판다스, IPython, 주피터 노트북, 그리고 scikitlearn을 모두 포함합니다. macOS, 윈도우, 리눅스를 모두 지원하며 매우 편리한 기능을 제공하므로 파이썬 과학 패키지가 없는 사람에게 추천하는 배포판입니다. Anaconda는 상용 라이브러리인 인텔 MKL(옮긴이 주_ 인텔 호환 프로세서를 위한 고성능 수학 라이브러리입니다. https://software.intel.com/en-us/intel-mkl) 라이브러리도 포함합니다. MKL을 사용하면(Anaconda를 설치하면 자동으로 사용할 수 있게 됩니다) scikit-learn의 여러 알고리즘이 훨씬 빠르게 동작합니다.
또 다른 과학 계산용 파이썬 배포판입니다. NumPy, SciPy, matplotlib, pandas, IPython을 포함하지만 무료 버전에는 scikit-learn이 들어 있지 않습니다. 학생과 학위수여가 되는 기관 종사자는 Enthought Canopy의 유료 버전을 무료로 받을 수 있는 아카데믹 라이선스를 신청할 수 있습니다. Enthought Canopy는 파이썬 2.7.x에서 작동하며 macOS, 윈도우, 리눅스에서 사용할 수 있습니다.
특별히 윈도우 환경을 위한 과학 계산용 무료 파이썬 배포판입니다. Python (x,y )는 NumPy, SciPy, matplotlib, pandas, IPython, scikit-learn을 포함합니다.
파이썬을 이미 설치했다면 다음과 같이 pip 명령을 사용하여 필요한 패키지들을 설치할 수 있습니다(2장에서 결정 트리를 그리기 위해서는 graphviz 패키지도 필요합니다. 자세한 내용은 깃허브를 참고하세요).

1.4 필수 라이브러리와 도구들
scikit-learn이 무엇이고 어떻게 사용하는지 아는 것이 중요하지만, 그 전에 꼭 알아둬야할 중요한 라이브러리들이 있습니다. scikit-learn은 파이썬 과학 라이브러리인 NumPy와 SciPy를 기반으로 만들었습니다. 우리는 NumPy와 SciPy 외에 pandas와 matplotlib도 사용할 것입니다. 그리고 브라우저 기반의 대화식 프로그래밍 환경인 주피터 노트북도 소개하겠습니다. scikit-learn을 십분 활용할 수 있도록 이런 도구들에 대해 간단히 소개하겠습니다. (옮긴이 주_ NumPy나 matplotlib에 익숙하지 않다면 SciPy 강의 노트(http://www.scipy-lectures.org/)의 1장을 읽어볼 것을 권합니다.)
1.4.1 주피터 노트북
주피터 노트북은 프로그램 코드를 브라우저에서 실행해주는 대화식 환경입니다. 이런 방식은 탐색적 데이터 분석에 아주 적합하여 많은 데이터 분석가가 주피터 노트북을 사용하고 있습니다. 주피터 노트북은 다양한 프로그래밍 언어를 지원하지만 우리는 파이썬만 사용하겠습니다. 그리고 주피터 노트북은 코드와 설명, 이미지들을 쉽게 섞어 쓸 수 있습니다. 사실 이 책 전부를 주피터 노트북으로 썼습니다. 이 책에 포함된 모든 예제 코드는 깃허브에서 내려받을 수 있습니다. (옮긴이 주_ 번역서의 코드는 scikit-learn 라이브러리의 최신 버전에 맞추었고 주석을 한글로 번역하였습니다. 원서의 깃허브 저장소 주소는 다음과 같습니다. https://github.com/amueller/introduction_to_ml_with_python)
1.4.2 NumPy
NumPy는 파이썬으로 과학 계산을 하려면 꼭 필요한 패키지입니다. 다차원 배열을 위한 기능과 선형 대수주(옮긴이 주_ 벡터, 행렬, 선형 변환을 연구하는 수학의 한 분야입니다.) 연산과 푸리에 변환주(옮긴이 주_ 시간의 함수인 신호 등을 주파수 성분으로 분해하는 변환입니다.) 같은 고수준 수학 함수와 유사pseudo 난수주(옮긴이 주_ 초깃값을 이용하여 이미 결정되어 있는 메커니즘에 의해 생성되는 난수로, 초깃값을 알면 언제든 같은 값을 다시 만들 수 있으므로 진짜 난수와 구별하여 유사 난수라 합니다.)생성기를 포함합니다.
scikit-learn에서 NumPy 배열은 기본 데이터 구조입니다. scikit-learn은 NumPy 배열 형태의 데이터를 입력으로 받습니다. 그래서 우리가 사용할 데이터는 모두 NumPy 배열로 변환되어야 합니다. NumPy의 핵심 기능은 다차원(n-차원) 배열인 ndarray 클래스입니다. 이 배열의 모든 원소는 동일한 데이터 타입이어야 합니다. 다음 코드는 NumPy 배열의 예입니다.

이 책에서는 NumPy를 아주 많이 사용할 것입니다. NumPy의 ndarray 클래스의 객체를 간단하게 NumPy 배열 혹은 그냥 배열이라고 부르겠습니다.
1.4.3 SciPy
SciPy는 과학 계산용 함수를 모아놓은 파이썬 패키지입니다. SciPy는 고성능 선형 대수, 함수 최적화, 신호 처리, 특수한 수학 함수와 통계 분포 등을 포함한 많은 기능을 제공합니다. scikit-learn은 알고리즘을 구현할 때 SciPy의 여러 함수를 사용합니다. 그중에서 가장 중요한 기능은 scipy.sparse입니다. 이 모듈은 scikit-learn에서 데이터를 표현하는 또 하나의 방법인 희소 행렬 기능을 제공합니다. 희소 행렬sparse matrix, 희박 행렬은 0을 많이 포함한 2차원 배열을 저장할 때 사용합니다.

보통 희소 행렬을 0을 모두 채운 2차원 배열로부터 만들지 않으므로(메모리가 부족할 수 있어서) 희소 행렬을 직접 만들 수 있어야 합니다. 다음은 COO 포맷(옮긴이 주_ Coordinate 포맷의 약자로 데이터가 놓일 행렬의 위치를 별도의 매개변수로 전달합니다. 한편 CSR은 ‘Compressed Row Storage’의 약자로 행의 인덱스를 압축하여 저장합니다.)을 이용해서 앞서와 동일한 희소 행렬을 만드는 예제입니다.
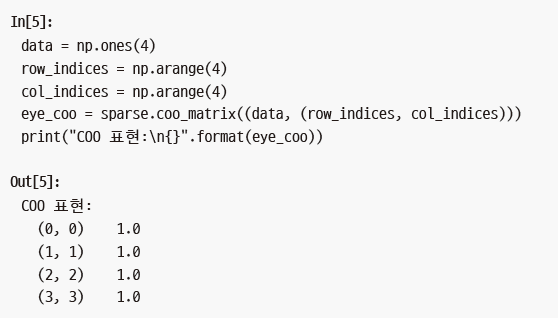
SciPy의 희소 행렬에 대한 자세한 내용은 SciPy 강의 노트(http://www.scipy-lectures.org)의 2.5절을 참고하세요.
1.4.4 matplotlib
matplotlib은 파이썬의 대표적인 과학 계산용 그래프 라이브러리입니다. 선 그래프, 히스토그램, 산점도 등을 지원하며 출판에 쓸 수 있을 만큼의 고품질 그래프를 그려줍니다. 데이터와 분석 결과를 다양한 관점에서 시각화해보면 매우 중요한 통찰을 얻을 수 있습니다. 이 책의 모든 그래프는 matplotlib을 사용했습니다. 주피터 노트북에서 사용 할 때는 %matplotlib notebook이나 %matplotlib inline 명령을 사용하면 브라우저에서 바로 이미지를 볼 수 있습니다. 대화식 환경을 제공하는 %matplotlib notebook 명령을 권장합니다(하지만 이 책에서는 %matplotlib inline을 사용합니다). 다음 코드는 [그림 1-1]의 그래프를 그리는 간단한 예제입니다.

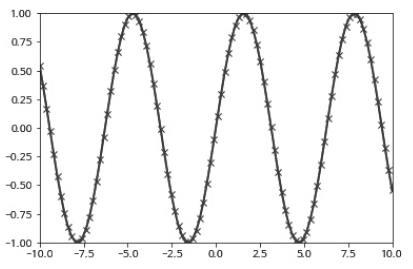
그림 1-1 matplotlib으로 그린 사인(sin) 함수
1.4.5 pandas
pandas는 데이터 처리와 분석을 위한 파이썬 라이브러리입니다. R의 data.frame을 본떠서 설계한 DataFrame이라는 데이터 구조를 기반으로 만들어졌습니다. 간단하게 말하면 pandas의 DataFrame은 엑셀의 스프레드시트와 비슷한 테이블 형태라고 할 수 있습니다. pandas는 이 테이블을 수정하고 조작하는 다양한 기능을 제공합니다.특히, SQL처럼 테이블에 쿼리나 조인을 수행할 수 있습니다. 전체 배열의 원소가 동일한 타입이어야 하는 NumPy와는 달리 pandas는 각 열의 타입이 달라도 됩니다(예를 들면 정수, 날짜, 부동소숫점, 문자열). SQL, 엑셀 파일, CSV 파일 같은 다양한 파일과 데이터베이스에서 데이터를 읽어 들일 수 있는 것이 pandas가 제공하는 또 하나의 유용한 기능입니다. 이 책은 pandas의 기능을 자세히 설명하지는 않습니다. 대신 pandas에 대한 훌륭한 안내서로 웨스 맥키니Wes Makinney가 쓴 『파이썬 라이브러리를 활용한 데이터 분석』(한빛미디어, 2013)을 추천합니다. 다음 코드는 딕셔너리를 사용하여 DataFrame을 만드는 간단한 예제입니다.

이 코드의 결과는 다음과 같습니다.
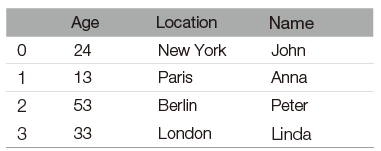
이 테이블에 질의하는 방법이 몇 가지 있는데, 다음은 그 예입니다.

다음은 이 코드를 실행한 결과입니다.

1.4.6 mglearn
이 책은 깃허브에 있는 코드와 병행해서 작성했습니다. 깃허브의 코드는 이 책의 예제뿐 아니라 mglearn 라이브러리도 포함합니다. 이 라이브러리는 그래프나 데이터 적재와 관련한 세세한 코드를 일일이 쓰지 않아도 되게끔 이 책을 위해 만든 유틸리티 함수들입니다. 혹시 궁금하다면 깃허브 저장소에서 함수 코드를 상세히 살펴볼 수 있습니다만, mglearn 모듈의 상세 사항은 이 책이 다루는 내용과 큰 관련이 없습니다. 이 책에서는 간단하게 그림을 그리거나 필요한 데이터를 바로 불러들이기 위해 mglearn을 사용합니다. 깃허브에 있는 노트북을 실행할 때는 이 모듈에 관해 신경 쓸 필요가 없습니다. 만약 다른 곳에서 mglearn 함수를 호출하려면, pip install
mglearn 명령으로 설치하는 것이 가장 쉬운 방법입니다.
[NOTE]
이 책은 NumPy, matplotlib, pandas를 많이 사용합니다. 따라서 모든 코드는 다음의 네 라이브러리를 임포트한다고 가정합니다.

또한 모든 코드는 주피터 노트북에서 실행되며 그래프를 표시하기 위해 %matplotlib notebook이나 %matplotlib inline 명령을 사용한다고 가정합니다. 만약 이런 매직 커맨드를 사용하지 않는다면 이미지를 그리기 위해 plt.show 명령을 사용해야 합니다.
1.5 파이썬 2 vs. 파이썬 3
현재 파이썬 2와 파이썬 3 버전이 모두 널리 쓰입니다. 가끔 이로 인해 사용자는 혼란을 겪기도 합니다. 파이썬 2는 더 이상 큰 개선은 진행되지 않으며 파이썬 3에서 변경 사항이 많아 파이썬 2로 작성한 코드는 파이썬 3에서 실행되지 않는 경우가 많습니다. 파이썬을 처음 쓰는 사람이거나 프로젝트를 새로 시작한다면 파이썬 3의 최신 버전을 사용하라고 권합니다. 파이썬 2로 작성한 기존 코드에 크게 의존하고 있다면 당장은 업그레이드를 미뤄야 합니다. 하지만 가능한 한 빨리 파이썬 3로 옮겨야 할 것입니다. 대부분의 경우 새로운 코드가 파이썬 2와 3에서 모두 실행되도록 작성하는 것은 어렵지 않습니다.(옮긴이 주_ six 패키지를 사용하면 손쉽게 이렇게 할 수 있습니다. https://pypi.python.org/pypi/six) 기존 소프트웨어와 연동하지 않아도 된다면 당연히 파이썬 3를 사용해야 합니다. 이 책의 모든 코드는 두 버전에서 모두 작동합니다. 하지만 파이썬 2에서는 출력 모양이 조금 다를 수 있습니다.

▼ 도서 살펴보기 (링크이동)


최신 콘텐츠

