IT/모바일
파이토치PyTorch는 2017년 초에 공개된 딥러닝 프레임워크로 개발자들과 연구자들이 쉽게 GPU를 활용하여 인공 신경망 모델을 만들고 학습시킬 수 있게 도와 줍니다. 파이토치의 전신이라고 할 수 있는 토치Torch는 루아 프로그래밍 언어로 되어 있었지만, 파이토치는 파이썬으로 작성되어 파이썬의 언어 특징을 많이 가지고 있습니다. 파이토치는 페이스북의 인공지능 연구팀AI Research 멤버들이 주로 관리하며, 독자적으로 운영되는 파이토치 포럼은 사람들이 질문을 올리면 프레임워크 개발자를 비롯한 많은 사람이 답을 해주는 등 활발히 교류가 일어나고 있습니다.
파이토치 공식 사이트( https://pytorch.org )
파이토치는 텐서플로 등 다른 프레임워크에 비해 여러 장점이 있는데, 이는 곧 살펴보겠습니다. 오픈에이아이OpenAI에서 근무하다가 현재는 테슬라에서 일하고 있는 안드레이 카파시Andrej Kaparthy는 파이토치를 쓰게 된 후 얼마나 몸과 마음이 건강해졌는지 트윗을 쓰기도 했습니다.
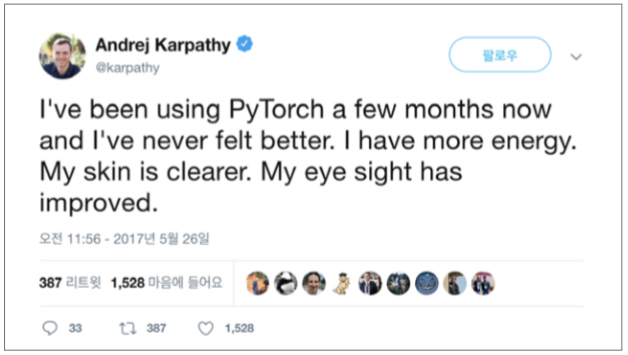
안드레이 카파시의 파이토치 사용 후기( https://twitter.com/karpathy/status/868178954032513024 )
오픈에이아이는 2015년 말 일론 머스크가 세운 비영리 인공지능 연구소로 세계적으로 인정받는 연구자들이 있는 회사입니다. 따라서 매우 다양한 모델과 프레임워크를 써봤을 텐데, 그중 파이토치가 가장 편리하다고 말할 정도면 파이토치가 확실히 장점이 있다는 것을 알 수 있습니다.
다른 프레임워크와의 비교
사실 처음 딥러닝을 접하는 분들에게는 파이토치에 이러이러한 장점이 있다고 설명해도 와닿기 어렵습니다. 먼저 파이썬에서 많이 쓰이는 넘파이NumPy 라이브러리와 파이토치를 비교해보고, 현재 많은 사람이 사용하는 다른 딥러닝 프레임 워크 텐서플로TensorFlow와의 비교를 통해 파이토치의 장점을 설명해보겠습니다.
먼저 넘파이만을 사용한 경우와 파이토치 프레임워크를 사용한 경우를 비교해봅시다. x, y, z 세 변수에 대해 학습하는 간단한 예를 생각해보면 기울기를 계산하기 위해 연산 그래프를 쭉 따라서 미분을 해야 합니다. 이때 넘파이만을 사용한다면 모든 미분 식을 직접 계산하고 코드로 작성해야 하므로 변수 하나당 두 줄씩 여섯 줄이 필요합니다. 반면 파이토치를 사용하면 이 과정을 자동으로 계산해주기 때문에 backward()라는 함수를 한 번 호출해주면 계산이 끝납니다.
또한 넘파이를 사용하는 것과 파이토치 프레임워크를 사용하는 것에는 또 하나의 큰 차이가 있습니다. 바로 GPU를 통한 연산 가능 여부입니다. 넘파이만으로 는 GPU로 값들을 보내 연산을 돌리고 다시 받는 것이 불가능합니다. 이에 비해 파이토치는 내부적으로 CUDA, cuDNN이라는 API를 통해 GPU를 연산에 사 용할 수 있고, 이로 인해 생기는 연산 속도의 차이는 엄청납니다. CUDA는 엔비디아가 GPU를 통한 연산을 가능하게 만든 API 모델이며, cuDNN은 CUDA를 이용해 딥러닝 연산을 가속해주는 라이브러리입니다.
병렬 연산에서 GPU의 속도는 CPU의 속도보다 월등히 빠르며 이 차이는 지속 적으로 벌어지고 있습니다. CUDA와 cuDNN을 둘 다 사용하면 연산 속도가 CPU의 15배 이상이 된다고 알려져 있습니다. CPU로 한 달 걸릴 연산을 이틀이면 할 수 있는 셈입니다. 심층 신경망을 만들 때 함수 및 기울기 계산, 그리고 GPU를 이용한 연산 가속 등의 장점이 있기 때문에 딥러닝 개발 시 프레임워크의 사용은 필수라고 할 수 있습니다.
널리 알려진 텐서플로와 파이토치를 비교해보면 어떨까요? 텐서플로와 파이토치는 둘 다 연산에 GPU를 이용하는 프레임워크입니다. 하지만 텐서플로는 연 산 그래프를 먼저 만들고 실제 연산할 때 값을 전달하여 결과를 얻는 ‘Define and Run’ 방식이고, 파이토치는 그래프를 만듦과 동시에 값이 할당되는 ‘Define by Run’ 방식입니다. 텐서플로의 ‘그래프를 먼저 정의하고 세션에서 실제로 값을 집어넣어 결과를 도출’하는 패러다임은 사람에 따라 직관적으로 받아들이기 어려울 수 있고, 그래프를 정의하는 부분과 이를 돌리는 부분이 분리되기 때문에 전체적으로도 코드 길이가 길어지게 됩니다. 반면 파이토치는 연산 그래프를 정의하는 것과 동시에 값도 초기화되어 연산이 이루어지는 ‘Define by Run’이므로 연산 그래프와 연산을 분리해서 생각할 필요가 없습니다.
또한 연산 속도에서도 차이가 있습니다. 연산 그래프를 고정해놓고 값만 전달하는 텐서플로가 더 빠른 환경도 있을 수 있겠지만, 텐서플로 깃허브에 올라온 이슈에 따르면 실험에 많이 사용되는 모델로 벤치마킹한 결과 파이토치가 텐서플 로보다 2.5배 빠른 결과가 나왔다고 합니다.이슈를 올린 사람이 실험 환경을 공개하여 다른 사람들이 같은 코드로 실험한 결과 역시 파이토치가 빠르게 나왔습니다. 모델마다, 사용한 함수마다 차이는 있겠지만 파이토치는 전반적으로 속도 면에서 텐서플로보다 빠르거나, 적어도 밀리지는 않는다고 할 수 있습니다.
텐서플로가 1년 정도 먼저 딥러닝이 뜨기 시작할 때 발표되어 사용자가 많은 것은 사실입니다. 이에 비해 파이토치는 뒤늦게 사람들에게 알려지고 있는 상태입니다. 텐서플로는 자체적으로 운영하는 포럼이 없고 구글 그룹도 편리하게 정리되어 있지는 않습니다. 반면 파이토치는 자체 운영 포럼이 있어서 질문을 올리면 파이토치 개발자들이 직접 답변을 달아주기도 합니다. 한국 커뮤니티를 보면 텐서플로는 Tensorflow-KR, 파이토치는 PyTorch-KR 페이스북 그룹이 있으며, 많은 사람이 질문을 올리거나 유용한 팁을 공유하고 있습니다.
파이토치에 대해 자세히 알아보기 →

이전 글 : 컴퓨팅과 여성
다음 글 : 최초의 버그와 최초의 컴파일러

최신 콘텐츠