유튜브 알고리즘을 타고 내 계정에 도착한 영상이 취향 저격했던 경험, 다들 있으시죠?
몇 년 전만 해도 알고리즘이 추천해 준 콘텐츠를 보는 것이 놀라운 일이었지만 이제는 쇼핑하거나 노래를 듣고, 전자책을 읽는 순간에 시스템으로부터 개인화된 추천을 다양하게 받고 있습니다. 한층 정교해진 딥러닝 기술은 고객의 요구사항을 정확히 간파하여 적절한 타이밍에 상품을 추천합니다. 대표적으로는 넷플릭스나 아마존 프라임 비디오의 콘텐츠 추천 시스템, 딥러닝 알고리즘을 통해 맞춤형 추천상품을 제공하는 네이버 AiTEMS 등을 이야기할 수 있죠.
추천시스템은 여러 사람에게 도움이 됩니다. 사용자 입장에서는 수많은 정보 속에서 나에게 필요한 상품과 콘텐츠를 빠르게 찾을 수 있고, 기업은 고객에게 시기적절한 콘텐츠를 추천하고, 상품 관여도를 증가시켜 매출 증대까지 이어갈 수 있습니다.
하지만 사용자를 현혹하는 상품 및 서비스를 제공할 만큼 매력적인 추천이 발생하려면 충분한 데이터가 필요합니다. 자체 머신러닝을 활용해 추천시스템을 구축한다면 인프라 관리에도 큰 공수가 들어가죠. 머신러닝 인프라 관리 걱정 없이 추천시스템을 운영할 수 있을까요?

규칙 기반 시스템과 실시간 동적 추천 시스템
간단한 추천 시스템은 종종 규칙 기반 시스템으로 시작합니다. 하지만 사용자와 상품의 수가 증가할수록 사용자 개개인에게 적합한 상품을 추천하는 시스템을 제공하는 특정한 규칙을 정의하기 어려워집니다. 즉, 광범위한 규칙은 고객을 현혹할 만큼 충분히 특화되지 못한다는 의미입니다.
머신러닝 기반 추천 시스템도 어려움에 직면할 때가 있습니다. 신규 고객이나 새로운 물품이 들어올 때에는 데이터가 쌓인 것이 전무하기 때문에 추천 시스템이 효력을 발휘하기 어렵습니다. 이는 전형적인 콜드 스타트(고객이나 제품에 대한 충분한 데이터가 없어 추천 시스템을 빌드하기 어려울 때)이며 현시대에 추천 시스템 엔진을 구현하는 개발자가 해결해야 하는 문제이기도 합니다.
추천 시스템은 인기 있는 항목만 추천하고 인기 없는 항목은 추천 하지 않는 함정에 빠지지 않도록 설계해야 합니다. 또한 애플리케이션을 사용하는 동안 사용자의 의도를 실시간으로 반영해야 하죠. 이를 위해선 데이터베이스에서 제공하는 사전 계산된 오프라인 추천 시스템 대신 실시간 동적 추천 시스템이 필요합니다.
이러한 동적 시스템을 통해 고객들은 관련성 있고 시기적절한 콘텐츠를 감상할 수 있으며, 기업들은 축적된 고객 개개인들의 경험으로부터 다음과 같은 이점들을 살릴 수 있습니다.
• 상품 관여도 증가: 사용자들에게 관련 콘텐츠를 추천함으로써 웹사이트에 머물러야 하는 동기를 부여하여 웹사이트의 점착성을 높이고 재방문 독려 가능
• 상품 전환 증가: 사용자는 자신이 구매하려는 상품과 관련성이 높은 상품을 구매하는 경향이 있음
• 클릭률 증가: 개별 사용자를 대상으로 개인 맞춤형 상품을 업데이트하여 상품의 클릭률 상승
• 매출 증대: 고객들에게 적재적소에 적절한 추천 시스템을 제공, 기업의 수익 증가
• 이탈 감소: 이탈률 및 이메일 광고의 수신 거부률 감소
수많은 머신러닝 솔루션이 있듯이, 개인화 시스템도 다양한 경우를 한 번에 해결해 줄 하나의 알고리즘 같은 것은 없습니다. 하지만, 개인별 상품 및 콘텐츠 추천을 만들 때 아마존의 광범위한 경험을 활용한다면 조금 더 빠르고 정확한 시스템을 구현할 수 있습니다.
아마존 퍼스널라이즈(AWS Personalize)는 개인화 기술을 만들어서 확장하고 관리하는 데 있어 아마존이 쌓아온 수십 년간의 경험을 반영합니다. 아마존 퍼스널라이즈를 사용하면 개발자들이 개인별 상품 추천 사항과 타깃 마케팅 프로모션을 쉽게 만들 수 있죠. 이런 AI 서비스를 통해 개발자들은 복잡한 자체 머신러닝 인프라 관리를 감당하지 않아도 되고 커스텀 개인화 모델을 빌드할 수 있습니다.
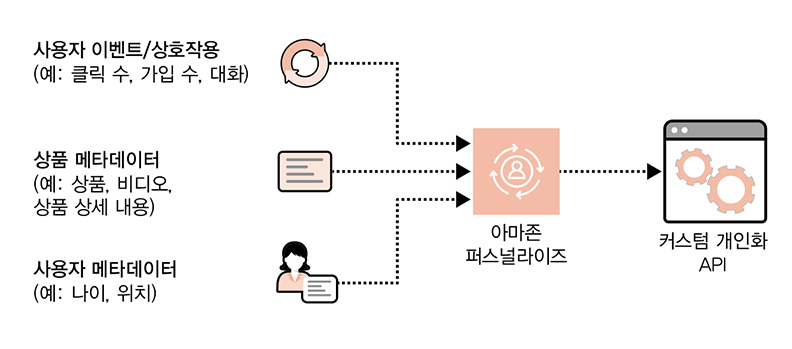
추천 시스템을 생성하려면 위의 그림과 같이 추천할 상품의 재고 품목과 함께 클릭 수, 페이지 수, 가입 수, 구매 수 등과 같은 지속적인 활동 데이터를 아마존 퍼스널라이즈에 제공하면 됩니다.
활동 데이터는 사용자가 시스템과 상호작용하는 방식에 대한 이벤트 정보로 구성됩니다. 이벤트 활동에는 사용자의 클릭 수, 장바구니에 추가한 항목 수, 구매한 물품 수, 시청한 영화 수 등이 포함되죠. 이러한 이벤트 활동은 효과적인 모델을 빌드하는 데 강력한 신호가 됩니다.
우리는 또한 상품 카테고리, 상품 가격, 사용자 연령, 사용자 위치 등과 같은 이벤트 활동에 관련된 사용자와 상품에 대한 추가 메타데이터를 아마존 퍼스널라이즈에 제공할 수 있습니다. 이 추가 메타데이터는 선택 사항이지만 어떤 상품을 추천하는 추천기를 빌드하는 표시로 사용할 기록 이벤트 활동이 거의 없거나 전혀 없는 ‘콜드 스타트’ 시나리오를 해결하는 데 유용할 수 있습니다.
이러한 이벤트 활동 데이터와 메타데이터를 통해 아마존 퍼스널라이즈는 사용자와 상품들에 대한 커스텀 추천기를 훈련하고, 조정하고, 배포합니다. 아마존 퍼스널라이즈는 피처 엔지니어링, 알고리즘 선택, 모델 튜닝 그리고 모델 배포까지 모든 머신러닝 파이프라인 스텝들을 수행합니다. 아마존 퍼스널라이즈가 데이터셋에 가장 적합한 모델을 선택하고 훈련하고 배포하면, 우리는 심플하게 get_recommendations() API를 호출해 사용자를 위한 실시간 추천 리스트를 생성할 수 있죠.
get_recommendations_response = personalize_runtime.get_recommendations(
campaignArn = "campaign_arn" #string
userId = "user_id" #string
)
item_list = get_recommendations_response['itemList']
recommendation_list = []
for item in item_list:
item_id = get_movie_by_id(item['itemId'])
recommendation_list.append(item_id)
수백만 개의 영화 평점이 담긴 인기 있는 훈련 데이터셋인 무비렌즈를 이용해 훈련된 아마존 퍼스널라이즈는 다음과 같은 결괏값을 생성합니다.

멀티태스크 추천기는 2개 이상의 목적에 대해 동시에 최적화하는 모델을 만듭니다. 이 모델은 모델 훈련 과정에서 작업 간 변수를 공유함으로써 전이학습을 수행하죠. 다음 텐서플로우 추천기 라이브러리 사용 예제는 추천기로 평점을 예측(다음 코드 예제의 rating_task 객체)하고 조회수를 예측(다음 코드 예제의 retrieval_task 객체)하도록 훈련시키는 방법을 보여줍니다.
user_model = tf.keras.Sequential([
tf.keras.layers.experimental.preprocessing.StringLookup(
vocabulary=unique_user_ids),
# 알 수 없는 토큰과 마스크 토큰을 처리하기 위해
# unique_user_ids 리스트 사이즈에 2를 더한다.
tf.keras.layers.Embedding(len(unique_user_ids) + 2, embedding_dimension)
])
movie_model = tf.keras.Sequential([
tf.keras.layers.experimental.preprocessing.StringLookup(
vocabulary=unique_movie_titles),
tf.keras.layers.Embedding(len(unique_movie_titles) + 2, embedding_dimension)on_list.append(item_id)
])
rating_task = tfrs.tasks.Ranking(
loss=tf.keras.losses.MeanSquaredError(),
metrics=[tf.keras.metrics.RootMeanSquaredError()],
)
rating_task = tfrs.tasks.Ranking(
retrieval_task = tfrs.tasks.Retrieval(on_list.append(item_id)
metrics=tfrs.metrics.FactorizedTopK(on_list.append(item_id)
candidates=movies.batch(128).map(self.movie_model)on_list.append(item_id)
)on_list.append(item_id)
)on_list.append(item_id)
아마존 세이지메이커는 세이지메이커 프로세싱 (SageMaker Processing) 서비스를 통해 서버리스 아파치 스파크를 (파이썬과 스칼라 언어 모두) 지원합니다.
이번 예제에서는 아마존 프로세싱 작업 서비스에 아파치 스파크 ML의 협업 필터링 알고리즘인 교대 최소 제곱법(Alternating Least Squares)을 실행해 추천값을 생성해 봅니다. 이미 스파크 기반 데이터 파이프라인이 있고 해당 파이프라인을 사용해 추천 시스템을 생성하는 경우 이 알고리즘을 사용합니다.
다음은 아파치 스파크 ML과 교대 최소 제곱법(ALS)으로 추천 시스템을 생성하는 예제입니다.
import pyspark
from pyspark.sql import SparkSession
from pyspark.sql.functions import *
from pyspark.ml.evaluation import RegressionEvaluator
from pyspark.ml.recommendation import ALS
from pyspark.sql import Row
def main():
...
lines = spark.read.text(s3_input_data).rdd
parts = lines.map(lambda row: row.value.split('::'))
ratingsRDD = parts.map(lambda p: Row(userId=int(p[0]),
movieId=int(p[1]),
rating=float(p[2]),
timestamp=int(p[3])))
ratings = spark.createDataFrame(ratingsRDD)
(training, test) = ratings.randomSplit([0.8, 0.2])
# 훈련 데이터에 대해 학습할 ALS 알고리즘을 이용한 추천기 빌드하기
als = ALS(maxIter=5,
regParam=0.01,
userCol='userId',
itemCol='itemId',
ratingCol='rating',
coldStartStrategy='drop')
model = als.fit(training)
# 테스트 데이터에 대한 RMSE를 계산하여 모델 평가하기
predictions = model.transform(test)(maxIter=5,
predictions = evaluator = RegressionEvaluator(metricName='rmse',
labelCol='rating',
predictionCol='prediction')
rmse = evaluator.evaluate(predictions)
# 각 사용자에 대한 상위 10개 추천 결과 생성하기
userRecs = model.recommendForAllUsers(10)
userRecs.show()
# 각 사용자에 대한 상위 10개 추천 결과 데이터 쓰기
userRecs.repartition(1).write.mode('overwrite')∖
.option('header', True).option('delimiter', '∖t')∖
.csv(f'{s3_output_data}/recommendations')
이제 세이지메이커 프로세싱 서비스를 이용해 서버리스 아파치 스파크 환경 내에서 파이스파크PySpark 스크립트를 실행해봅니다.
from sagemaker.spark.processing import PySparkProcessor
from sagemaker.processing import ProcessingOutput
processor = PySparkProcessor(base_job_name='spark-als',
role=role,
instance_count=1,
instance_type='ml.r5.2xlarge',
max_runtime_in_seconds=1200)
processor.run(submit_app='train_spark_als.py',
arguments=['s3_input_data', s3_input_data,
's3_output_data', s3_output_data,
],
logs=True,
wait=False
)
아래의 출력 예시는 위의 스파크 프로세싱 작업을 마친 후 훈련된 알고리즘을 이용해 생성한 결과를 보여줍니다. 이 출력 결과에는 3개의 user ID에 대한 추천값을 [item ID, rank] 리스트들을 나열해 2차원 행렬로 보여주고 있습니다. 각 recommendations 행은 rank 값에 대한 내림차순으로 나열합니다. rank 값이 높을수록 추천을 많이 하는 것이고, 작은 값은 그 반대죠.

이 글은 도서 『AWS 기반 데이터 과학』 내용 중 일부를 편집하여 작성되었습니다.
머신러닝을 엣지에 도입하든, 인공지능과 머신러닝 여정의 시작 단계에 있든, 컴퓨터 비전·강화 학습·적대적 생성 네트워크(GAN)를 시작할 수 있는 재미있는 교육 방법을 찾고 있든지 간에 우리는 바로 사용할 수 있는 AI 서비스로 우리의 애플리케이션을 풍부하게 만들 수 있습니다.
아마존 클라우드 분야 베스트셀러! AWS를 기반으로 데이터 과학 프로젝트를 진행하는 모든 이를 위한 『AWS 기반 데이터 과학』에서 더 많은 정보를 확인해 보세요.


최신 콘텐츠