IT/모바일
전형적인 머신러닝 프로젝트의 순서는 다음과 같습니다.
- 데이터를 분석합니다.
- 모델을 선택합니다.
- 훈련 데이터로 훈련을 시킵니다.
- 잘 일반화되기를 기대하면서 새 데이터 모델을 적용해 예측을 만듭니다.
보시다시피, 머신러닝 프로젝트에서는 모델을 선택해서 어떤 데이터에 훈련시키는 것이 주요 작업이기 때문에 ‘나쁜 모델’과 ‘나쁜 데이터’가 있다면 문제가 될 수 있습니다. 우선 두 가지 도전 과제 중 나쁜 데이터의 사례부터 확인해 보겠습니다.
1. 충분하지 않은 양의 훈련 데이터
어린아이에게 사과에 대해 알려주려면 사과를 가리키면서 ‘사과’라고 말하기만 하면 됩니다(아마도 이 과정을 여러 번 반복해야 할 것입니다). 그러면 아이는 색상과 모양이 달라도 모든 종류의 사과를 구분할 수 있습니다. 정말 똑똑하죠.
머신러닝은 아직 이렇게까지는 못합니다. 대부분의 머신러닝 알고리즘이 잘 작동하려면 데이터가 많아야 합니다. 아주 간단한 문제에서도 수천 개의 데이터가 필요하고 이미지나 음성 인식 같은 복잡한 문제라면 수백만 개가 필요할지도 모릅니다 (이미 만들어진 모델을 재사용할 수 없다면 말이죠).
✅ 믿기 힘든 데이터의 효과
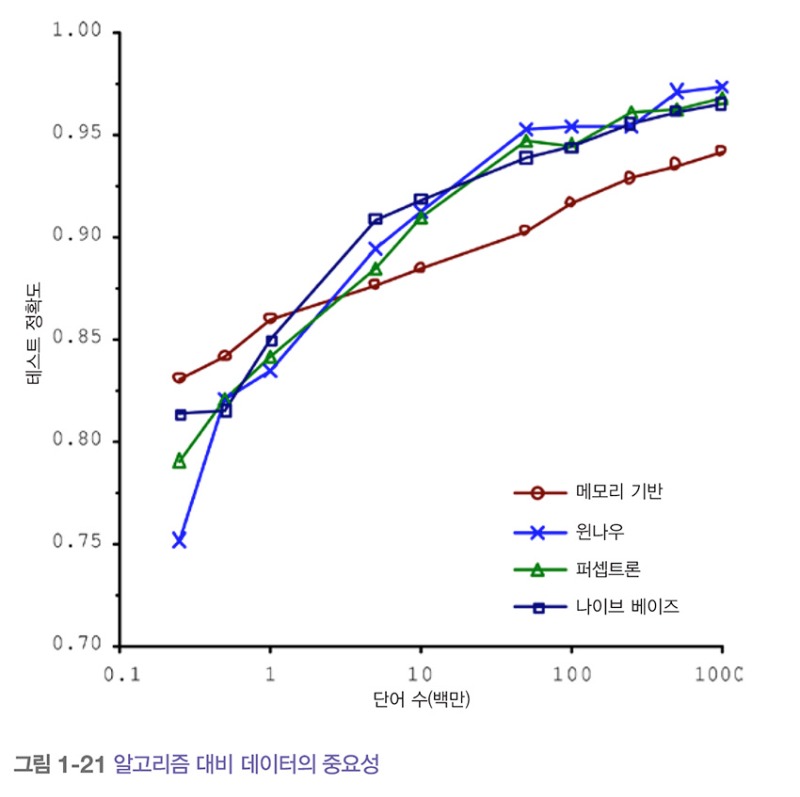
마이크로소프트 연구자인 미셸 반코와 에릭 브릴은 2001년에 발표한 논문에서 충분한 데이터가 주어지면 아주 간단한 모델을 포함하여 여러 다른 머신러닝 알고리즘이 복잡한 자연어 중의성 해소 문제를 거의 비슷하게 잘 처리한다는 사실을 보여주었습니다(그림 1-21).
저자들의 말처럼 이러한 결과는 시간과 돈을 알고리즘 개발에 쓰는 것과 말뭉치corpus 개발에 쓰는 것 사이의 트레이드 오프trade off를 다시 생각해봐야 한다는 점을 시사합니다.
복잡한 문제에서 알고리즘보다 데이터가 더 중요하다는 생각은 2009년 피터 노르빅 등이 쓴 「The Unreasonable Effectiveness of Data」 논문 때문에 더 유명해졌습니다.
하지만 기억할 점은 여전히 소규모 또는 중간 규모의 데이터셋이 매우 흔하고, 훈련 데이터를 추가로 모으는 것이 항상 쉽거나 저렴한 일은 아니므로, 아직은 알고리즘을 무시하지 말아야 한다는 것입니다.
2. 대표성 없는 훈련 데이터
일반화가 잘되려면 훈련 데이터가 일반화하고 싶은 새로운 사례를 잘 대표하는 것이 중요합니다. 이는 사례 기반 학습이나 모델 기반 학습 모두 마찬가지입니다.
예를 들어 앞서 선형 모델을 훈련시키기 위해 사용한 국가 데이터는 1인당 GDP가 23,500달러보다 적거나 62,500달러보다 많은 나라가 빠져 있어 대표성이 완벽하지 못합니다. [그림1-22]는 누락된 나라를 추가했을 때 데이터가 어떻게 나타나는지 보여줍니다.
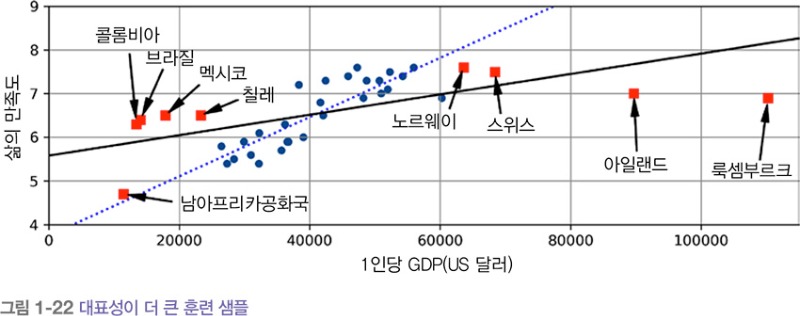
이 데이터에 선형 모델을 훈련시키면 실선으로 된 모델을 얻습니다. 반면 이전 모델은 점선으로 나타나 있습니다. 그림에서 알 수 있듯이 누락된 나라를 추가하면 모델이 크게 변경되며 이런 간단한 선형 모델은 잘 작동하지 않는다는 걸 확실히 보여줍니다. 매우 부유한 나라가 중간 정도의 나라보다 행복하지 않고(실제로도 더 행복해 보이지 않습니다), 반대로 일부 가난한 나라가 부유한 나라보다 행복한 것 같습니다.
대표성 없는 훈련 데이터를 사용했으므로 정확한 예측을 하지 못하는, 특히 매우 가난하거나 부유한 나라에서 잘못 예측하는 모델을 얻었습니다.
일반화하려는 사례들을 대표하는 훈련 세트를 사용하는 것이 매우 중요하지만 이게 생각보다 어려울 때가 많습니다. 샘플이 작으면 샘플링 잡음sampling noise (우연에 의한 대표성 없는 데이터)이 생기고, 매우 큰 샘플도 표본 추출 방법이 잘못되면 대표성을 띠지 못할 수 있습니다. 이를 샘플링 편향 sampling bias이라고 합니다.
✅ 유명한 샘플링 편향 사례
아마도 샘플링 편향에 대한 가장 유명한 사례는 랜던과 루스벨트가 경쟁했던 1936년 미국 대통령 선거에서 『The Literary Digest』 잡지사가 천만 명에게 우편물을 보내 수행한 대규모 여론 조사일 것입니다. 240만 명의 응답을 받았고, 랜던이 선거에서 57%의 득표율을 얻을 것이라고 높은 신뢰도로 예측했습니다.
하지만 루스벨트가 62%의 득표율로 당선되었습니다. 문제는 『The Literary Digest』의 샘플링 방법에 있었습니다.
첫째, 여론 조사용 주소를 얻기 위해 전화번호부, 자사의 구독자 명부, 클럽 회원 명부 등을 사용했습니다. 이런 명부는 모두 공화당(랜던)에 투표할 가능성이 높은 부유한 계층에 편중된 경향이 있습니다.
둘,우편물 수신자 중 25% 미만의 사람이 응답했습니다. 이 역시 정치에 관심 없는 사람, 『The Literary Digest』를 싫어하는 사람과 다른 중요한 그룹을 제외시켜 표본을 편향되게 만들었습니다. 특히 이러한 종류의 샘플링 편향을 비응답 편향nonresponse bias이라고 합니다.
다른 예로 펑크 음악 비디오를 분류하는 시스템을 만든다고 가정합시다. 이를 위한 훈련 세트를 유튜브에서 ‘펑크 음악’을 검색해 마련할 수 있습니다. 하지만 이는 유튜브 검색 엔진이 결괏값으로 유튜브 내의 모든 펑크 음악을 대표하는 동영상을 반환한다고 가정하는 것입니다.
현실에서는 검색 결과가 인기 음악가들로 편중될 가능성이 큽니다 (브라질에 살고 있다면 펑크 음악의 아버지라 불리는 제임스 브라운과 전혀 상관없는 ‘펑크 카리오카’ 동영상을 결과로 보게 될 것입니다). 그렇다면 어떻게 대량의 훈련 세트를 구할 수 있을까요?
3. 낮은 품질의 데이터
훈련 데이터가 오류, 이상치, (성능이 낮는 측정 장치로 인한) 잡음으로 가득하다면 머신러닝 시스템이 내재된 패턴을 찾기 어려워 제대로 작동하지 않을 것입니다. 그렇기 때문에 훈련 데이터 정제에 시간을 투자할 만한 가치는 충분합니다. 사실 대부분의 데이터 과학자가 데이터 정제에 많은 시간을 쓰고 있습니다. 다음은 훈련 데이터 정제가 필요한 경우입니다.
• 일부 샘플이 이상치라는 게 명확하면 해당 샘플들을 무시하거나 수동으로 잘못된 것을 고치는 것이 좋습니다.
• 일부 샘플에 특성 몇 개가 빠져있다면 이 특성을 모두 무시할지, 이 샘플을 무시할지, 빠진 값을 채울지, 또는 이 특성을 넣은 모델과 제외한 모델을 따로 훈련시킬 것인지 결정해야 합니다.
4. 관련없는 특성
속담에도 있듯이 엉터리가 들어가면 엉터리가 나옵니다garbage in, garbage out. 훈련 데이터에 관련없는 특성이 적고 관련 있는 특성이 충분해야 시스템이 학습할 수 있을 것입니다. 성공적인 머신러닝 프로젝트의 핵심 요소는 훈련에 사용할 좋은 특성들을 찾는 것입니다.
이 과정을 특성 공학feature engineering이라 하며 다음과 같은 작업을 포함합니다.
• 특성 선택feature selection : 가지고 있는 특성 중에서 훈련에 가장 유용한 특성을 선택합니다.
• 특성 추출feature extraction : 특성을 결합하여 더 유용한 특성을 만듭니다. 앞서 본 것처럼 차원 축소 알고리즘이 도움이 될 수 있습니다.
• 데이터 수집 : 새로운 데이터를 수집해 새 특성을 만듭니다.
지금까지 나쁜 데이터의 사례를 살펴보았고 이제 나쁜 알고리즘의 예를 몇 가지 살펴보겠습니다.
5. 훈련 데이터 과대적합
해외 여행 중 택시 운전사가 여러분의 물건을 훔쳤다고 가정합시다. 아마도 그 나라의 모든 택시 운전사를 도둑이라고 생각할 수도 있습니다. 사람은 종종 과도하게 일반화를 하지만 주의하지 않으면 기계도 똑같은 함정에 빠질 수 있습니다.
머신러닝에서는 이를 과대적합overfitting이라고 합니다. 모델이 훈련 데이터에는 너무 잘 맞지만 일반성이 떨어진다는 뜻입니다.
[그림 1-23]은 고차원의 다항 회귀 모델이 삶의 만족도 훈련 데이터에 크게 과대적합된 사례를 보여줍니다. 간단한 선형 모델보다 이 모델이 훈련 데이터에 더 잘 맞는다 하더라도 실제로 이 예측을 믿기는 힘듭니다.
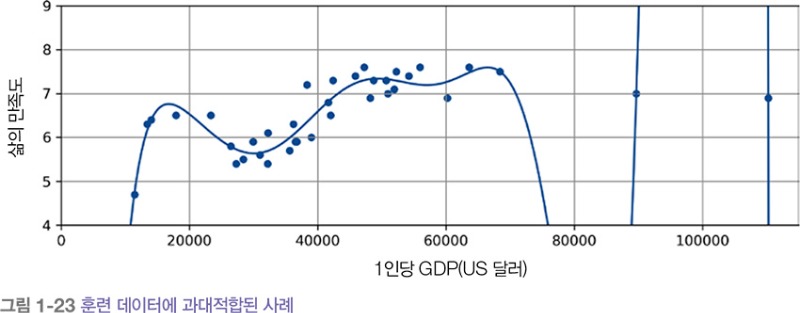
심층 신경망 같은 복잡한 모델은 데이터에서 미묘한 패턴을 감지할 수 있지만, 훈련 세트에 잡음이 많거나 데이터셋이 너무 작으면 (택시 운전사의 예처럼) 샘플링 잡음이 발생하므로 잡음이 섞인 패턴을 감지하게 됩니다. 당연히 이런 패턴은 새로운 샘플에 일반화되지 못합니다.
삶의 만족도 모델에 나라 이름 같은 관련없는 특성을 많이 추가한다고 가정해봅시다. 이 경우 복잡한 모델이 이름에 ‘w’가 들어간 나라들의 삶의 만족도가 7보다 크다는 패턴을 감지할지 모릅니다..
뉴질랜드(7.6), 노르웨이(7.3), 스웨덴(7.2), 스위스(7.5)가 여기에 속합니다. 이 w-만족도 규칙을 르완다나 짐바브웨에 일반화하면 얼마나 신뢰할 수 있을까요? 확실히 이 패턴은 우연히 훈련 데이터에서 찾은 것이지만 이 패턴이 진짜인지 잡음 데이터로 인한 것인지 모델이 구분해낼 방법은 없습니다.
모델을 단순하게 하고 과대적합의 위험을 줄이기 위해 모델에 제약을 가하는 것을 규제regularization라고 합니다. 예를 들어 앞서 만든 선형 모델은 두 개의 모델 파라미터 θ0과 θ1을 가지고 있습니다.이는 훈련 데이터에 모델을 맞추기 위한 두 개의 자유도degree of freedom를 학습 알고리즘에 부여합니다. 모델은 직선의 절편(θ0)과 기울기(θ1)를 조절할 수 있습니다.
우리가 θ1=0이 되도록 강제하면 알고리즘에 한 개의 자유도만 남게 되고 데이터에 적절하게 맞춰지기 힘들 것입니다. 즉, 할 수 있는 것이 훈련 데이터에 가능한 한 가깝게 되도록 직선을 올리거나 내리는 것이 전부이므로 결국 평균 근처가 됩니다. 진짜 아주 간단한 모델이네요!
알고리즘이 θ1을 수정하도록 허락하되 작은 값을 갖도록 유지시키면 학습 알고리즘이 자유도 1과 2 사이의 적절한 어딘가에 위치할 것입니다. 이는 자유도 2인 모델보다는 단순하고 자유도 1인 모델보다는 복잡한 모델을 만듭니다. 데이터에 완벽히 맞추는 것과 일반화를 위해 단순한 모델을 유지하는 것 사이의 올바른 균형을 찾는 것이 좋습니다.
다음 그림에는 세 가지 모델이 있습니다.
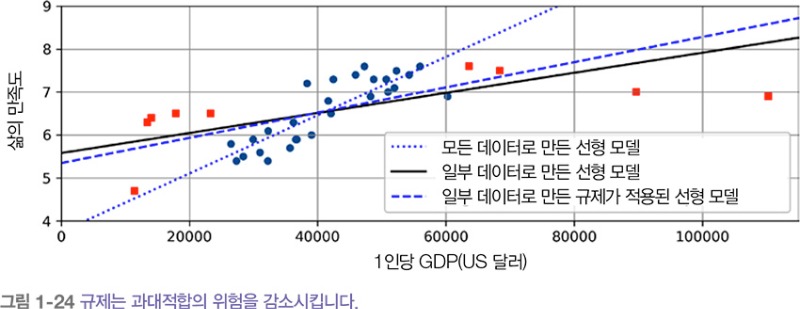
• 점선은 (사각형으로 표시된 나라를 제외하고) 동그라미로 표시된 나라로 훈련한 원래 모델
• 파선은 모든 나라(동그라미와 사각형)를 포함해 훈련한 두 번째 모델
• 실선은 첫 번째 모델과 같은 데이터에 규제를 적용해 만든 선형 모델
규제가 모델의 기울기를 더 작게 만들었습니다. 이 모델은 훈련 데이터(동그라미)에는 덜 맞지만 훈련하는 동안 못 본 새로운 샘플(사각형)에는 더 잘 일반화됩니다.
학습하는 동안 적용할 규제의 양은 하이퍼파라미터hyperparameter가 결정합니다. 하이퍼파라미터는 (모델이 아니라) 학습 알고리즘의 파라미터입니다. 그래서 학습 알고리즘으로부터 영향을 받지 않으며, 훈련 전에 미리 지정되고, 훈련하는 동안에는 상수로 남아 있습니다. 규제 하이퍼파라미터를 매우 큰 값으로 지정하면 (기울기가 0에 가까운) 거의 평편한 모델을 얻게 됩니다.
그러면 학습 알고리즘이 훈련 데이터에 과대적합될 가능성은 거의 없겠지만 좋은 모델을 찾지 못합니다. 머신러닝 시스템을 구축할 때 하이퍼파라미터 튜닝은 매우 중요한 과정입니다(책 『핸즈온 머신러닝(3판)』 2장에서 자세한 예를 다룹니다).
6. 훈련 데이터 과소적합
이미 짐작했겠지만 과소적합underfitting은 과대적합의 반대입니다. 이는 모델이 너무 단순해서 데이터의 내재된 구조를 학습하지 못할 때 일어납니다. 예를 들어 삶의 만족도에 대한 선형 모델은 과소적합되기 쉽습니다. 현실은 이 모델보다 더 복잡하므로 훈련 샘플에서조차도 부정확한 예측을 만들 것입니다.
이 문제를 해결하는 주요 기법은 다음과 같습니다.
• 모델 파라미터가 더 많은 강력한 모델을 선택합니다.
• 학습 알고리즘에 더 좋은 특성을 제공합니다.
• 모델의 제약을 줄입니다.
이 글은 도서 『핸즈온 머신러닝(3판)』 내용에서 일부를 발췌, 작성하였습니다. 이 책은 이론과 실습을 아우르며 머신러닝과 딥러닝의 세계를 안내합니다. 파이썬 프로그래밍 경험만 있다면 도전해 보세요. 누구나 머신러닝 전문가가 될 수 있습니다.

이전 글 : AutoML로 완전한 자동화를 달성할 수 있을까?

최신 콘텐츠